

【是否原创】是
【首发渠道】TiDB 社区
故事背景
前段时间上线了一个从Oracle迁移到TiDB的项目,某一天应用端反馈有一个诡异的现象,就是有张小表做全表delete的时候执行比较慢,而且有越来越慢的迹象。这个表每次删除的数据不超过20行,那为啥删20行数据会这么慢呢,我们来一探究竟。
问题排查
根据应用端提供的表名去慢查询里面搜索,确实发现了大量全表删除的SQL:

从列表中找一条来看看具体的时间分布:
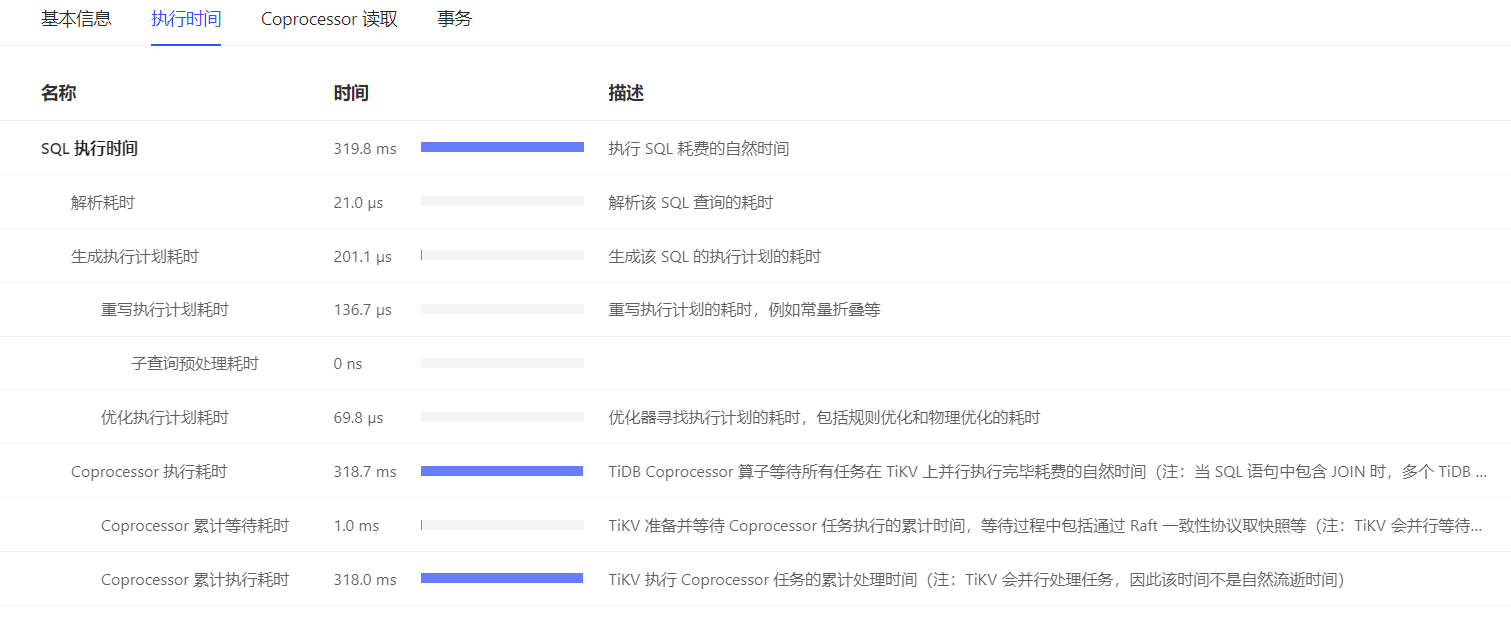
可以发现绝大部分时间都花了Coprocessor阶段,这个阶段表示请求已经被下推到了TiKV执行,我们继续看看在TiKV里面都做了些什么。一看吓一跳,一个很“小”表的删除竟然会扫描了成千上万个key:

这一点我们也可以从执行计划中得出结论,时间几乎都花在了数据扫描上面:
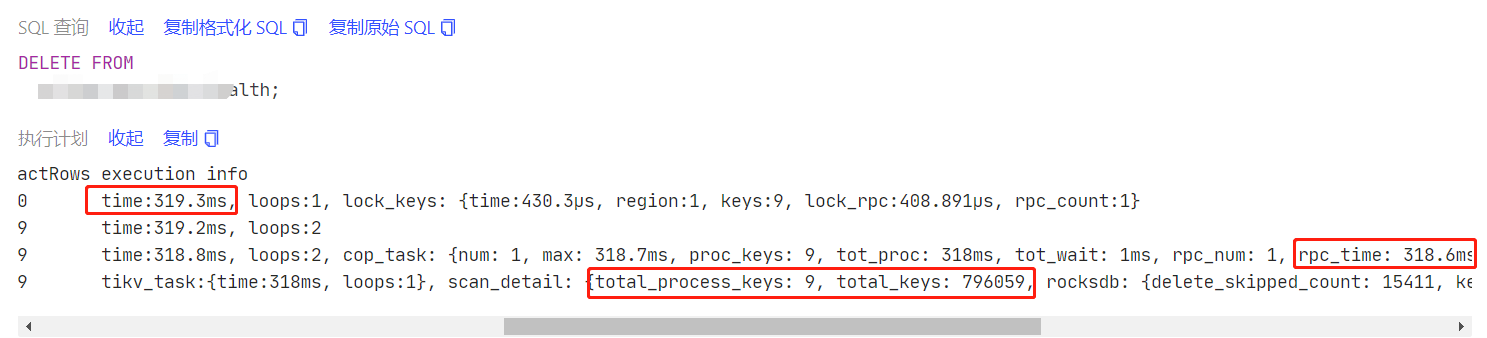
到这里为止基本就能判断出慢的原因就在于扫描了很多无效的key,上面这个例子最终删除的数据只有9行,但是却扫描了近80万个key,很明显这是由GC引发的一个惨案,因为这个集群中gc_life_time设置的是48h。至于为什么要设置这么大,其中的故事我们不去讨论。
问题似乎很简单,但是这里面涉及到的知识点很多也非常重要,我觉得有必要做一次系统梳理,防止新手踩坑。
删数据的原理解析
要搞清楚删除数据的原理,有几个东西你必须要知道:
- TiDB的GC和MVCC
- Region的概念以及Key的构成
熟悉TiDB的朋友都知道,TiKV底层是直接使用Rocksdb来存储kv数据,而Rocksdb使用的是LSM tree这种数据结构,它是一种append only模型,也就是说所有对数据的变更都体现在追加上。
这是什么意思呢?比如说对一行数据做update,体现在存储上的并不是找到原来的数据直接更新,而是新增一行数据,同时把原来的数据标记为旧版本,这些历史版本就构成了MVCC,同理delete也是一样,并不是直接把原数据删了,而是一种逻辑删除。
那究竟要保留多少历史版本,如何去清理这些历史版本呢,这个就是由GC单元去处理。系统变量tidb_gc_life_time和tidb_gc_run_interval可以控制GC的行为,tidb_gc_life_time定义了历史版本保留的时间,tidb_gc_run_interval定义了GC运行的周期,它们默认都是10分钟。
Region是TiDB中对数据进行划分的一种逻辑概念,是数据调度的最小单位,TiDB对数据的分片也体现在Region上。它是由一段连续的key范围组成,我们可以通过如下方式查询某张表由哪些Region组成:
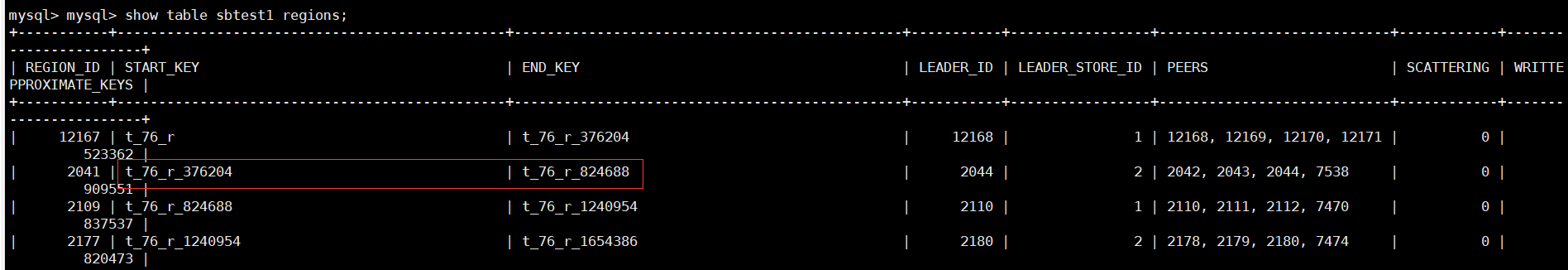
Region里的key是一种有规则的编码,数据和索引都是以如下的方式转换为KV键值对,最终存储在Rocksdb中:
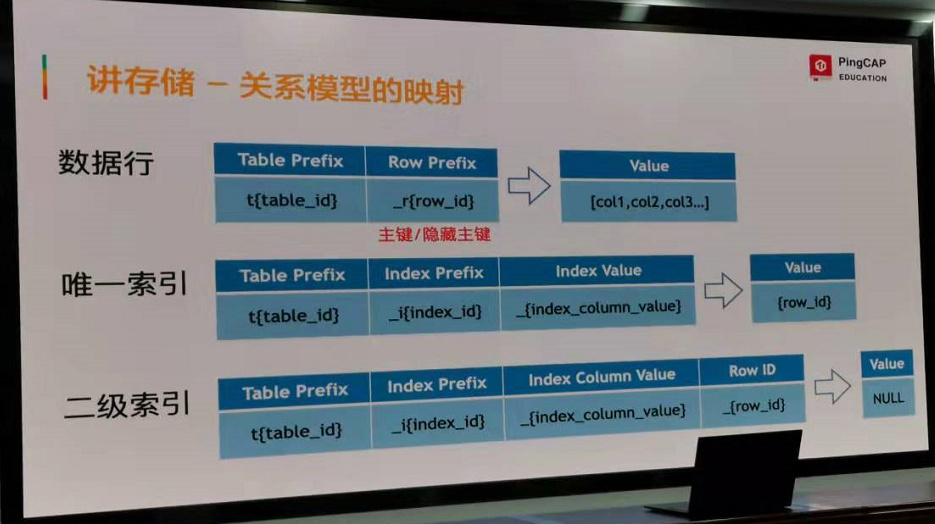
我们可以发现同一张表里的数据,它的key前缀都是相同的,这样就方便对表进行范围查找。
大家有可能看到的startkey和endkey中tableid不是同一个,这种是正常现象,因为对于比较小的表是存在多个表共用一个Region的。
结合前面介绍的GC和Region概念,可以发现如下可能存在的问题(摘自官网文档):
在数据频繁更新的场景下,将 tidb_gc_life_time 的值设置得过大(如数天甚至数月)可能会导致一些潜在的问题,如:
- 占用更多的存储空间。
- 大量的历史数据可能会在一定程度上影响系统性能,尤其是范围的查询(如 select count(*) from t)。
所以说,一旦涉及到范围查询并且没有索引的情况下,GC对性能的影响就非常大。恰巧本文的这个delete整张表场景就是典型的全表扫描,这里的全表扫描指的是扫描这个表包含的所有历史版本key,而不仅仅是当前你能看到的那些数据。因此,对大表千万千万不要这样清数据,它相当于全表扫一遍,再全表写一遍,非常恐怖。
大家是不是普遍认为,我只删9条数据那就扫描这9条数据的key就好了,为什么要扯上那么多无关的key?我也认为应该是这样的,可能实现上有TiDB自己的考虑吧(或许是一个个key去判断效率更慢?)。
既然我们改变不了这个现状,那么如何用正确的方式去删数据就是要重点关心的了。
删数据的最佳实践
实际场景中,删数据不外乎以下几种情况:
- 对某张表按过滤条件批量删除
- 删除某张表的全部数据,俗称清表
- 删表
- 删库
对于第一种,如果结果集很大,最佳做法是把过滤条件进行细化,一批一批的去删。它的好处是首先不容易触发大事务限制,其次能够减少误删的情况。不仅仅是批量删除,批量更新也应该是同样的做法,把条件拆的更细一些。我常用的做法是,按过滤条件找出对应数据行的rowid,然后把这些rowid进行分段,对这一段的范围做更新或删除,这样能极大提升操作效率。
对于第二种全表删除,极力推荐使用truncate,它相当于删表重建新表,所以tableid必然是和以前不一样了,那就肯定不会扫描到历史版本数据,删表建表也只涉及到元数据操作,速度很快。还有一点,truncate数据以后,被GC扫过的历史数据会直接清掉释放出存储空间,delete操作则不会释放,要等到compaction才能被再次利用。
对于第三种,没得选了,只有drop table。
对于第四种,也只有drop database。
那么问题来了,以上几种删数据的方式,万一是误删你想好了如何快速恢复吗?还是想直接paolu。。。
TiDB开发规范
在这个项目中经历过好几次大批量修复数据造成数据库不稳定的情况,因为这个系统的开发者和DBA都是Oracle背景,他们习惯了一上来就一条SQL对上亿的大表做批量操作,这显然在TiDB中不太适用,动不动就是SQL OOM或者各种too large,再就是导致CPU和内存飙升。
我觉得TiDB开发规范在早期的技术选型中就应该是要被重点考虑的一环,要充分了解TiDB的使用方式和限制条件是否能被开发运维团队接受。确定使用TiDB以后,开发和运维人员还要继续去落实执行,特别是一些高频使用场景,这样才能达到事半功倍的效果。
就比如常见的加索引,TiDB在有了数据以后加索引是特别慢的,而且是个串行操作。如果你发现有个join查询特别慢,需要给两张表分别加上索引,是马上就加吗,先加哪一个,加几个合适?
社区里有一篇非常全的开发规范说明值得每一位去细读,希望大家都能收藏,时不时翻出来看看。

【是否原创】是 【首发渠道】TiDB 社区 【目录】 一、前言 1.目的 2.适用范围 3.高亮示意 4.注意事项 二、对象命名规范 1.原则 2.数据库命名规范 3.表命名规范 4.字段命名规范 5.索引命名规范 三、数据库对象设计 1.表的设计 2.字段的设计 3.字段默认值 4.索引设计 5.权限设计 四、数据模型设计 1.完整性 2.性能 3.…
总结
本文提到的场景只是这个项目中的一个缩影,因为项目周期原因应用端很多不好的SQL(你能想象到还有where or几千个条件?)都没有来得及优化,所以暴露出了正确使用TiDB的重要性。
没有绝对完美的产品,我们要充分了解它的原理,使用的时候做到扬长避短,这样既能发挥它的价值也能提升我们的效率。