

【是否原创】是
【首发渠道】TiDB 社区,谢绝转载
第一次在社区写文章,文笔不行,只是想分享一些经验,功力不到之处,还望海涵。
背景描述
我是一个数据工程师,我司维护了一个互联网在线销售系统。因用户规模和数据量的原因,数据链路采用如下架构设计:

数据从业务库(多组Mysql集群-MHA方案)通过binlog实时同步到kv数据库中,每日定时抽取数据到hadoop中,加工后,在同步到汇总库(Mysql,多实例,类似主题库)中。
问题分析
年中时,某项目现场同事向我反馈了一个问题,用户发现日汇总数据不对,在使用明细数据查询(业务库)和日汇总(汇总库)核对时,发现差异,因某原因此种情况与用户本身利益密切相关,用户反应强烈。
此功能相关表,在千万级别,是频繁更新的表。客户反应多集中在月初或者月末,受影响的客户小于2‰,基本无法跟踪。经过几周的排查,问题排查到mysql到hadoop之间的同步环节上,但发现不了最终问题,此时情况严重,影响到项目结项。
经过团队的讨论,解决问题的思路转换到替换组件上,既然发现不了问题,能否在再增加一个同步链路,每日同步后,对两份数据求合集,进一步缩小受影响的范围。
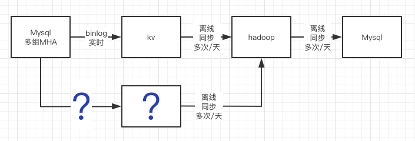
对冗余链路有几个要求:
- 仍然坚持binlog同步,影响最小。
- 同步稳定,同步并发能力要高。
- 方案成熟,是公司内部已经用过,至少预研测试过的方案。
- 同步到Hive时,吞吐能力大,能够在合理的时间,同步完所有数据。
首先想到的是TiDB,因为TiDB本身是个分布式的关系数据库,数据一致性能得到保障。
公司内部有用过otter做mysql之间的数据同步,otter架构如下:
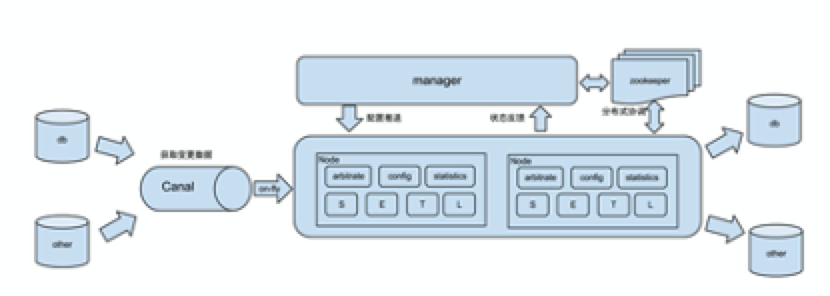
项目参考:https://github.com/alibaba/otter/
虽然此项目很久没人维护,但从使用反馈来看比较好。
方案测试
由于时间紧,可用资源有限,我们对尽可能利用闲置资源做了一些测试。
我们对TiDB做了tpcc测试,测试过程参考:https://docs.pingcap.com/zh/tidb/stable/benchmark-tidb-using-tpcc
我们的测试环境是
- 1TiDB 8C32G SSD
- 3TiKV 8C32G SSD
- 128并发线程
数据仓库300个单位,30个分区,其中各表数据量:
| 表名 | 数据量 |
|---|---|
| customer | 9000000 |
| district | 3000 |
| history | 9052121 |
| item | 100000 |
| new_order | 2705417 |
| order_line | 90615072 |
| orders | 9069285 |
| stock | 30000000 |
| warehouse | 300 |
测试结果如下:

我们也对TiDB做了Spark读取写入测试,使用方式参考:https://docs.pingcap.com/zh/tidb/stable/get-started-with-tispark
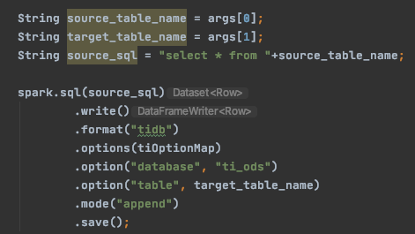
代码很简单:
写入代码:
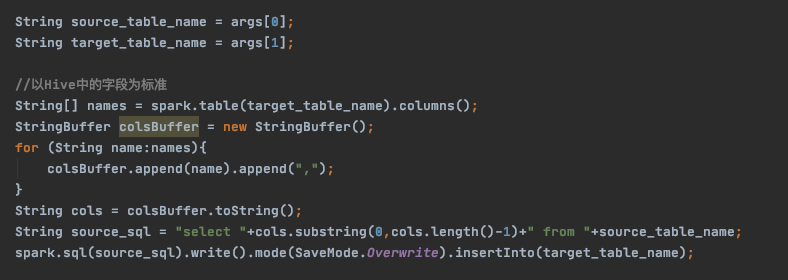
读取代码:
测试结果如下:
写:16台8C16G机器,SSD磁盘,2000万数据,平均7分钟(预写:1.5分钟,提交:2.3分钟)。
读:16台8C16G机器,SSD磁盘,2亿5千万,平均3.3分钟。
问题解决
结合以上的测试结果,TiDB的写入速度与TiSpark的读写速度都可以满足要求。本着死马当活马医的精神,拍脑袋决定,方案如下:
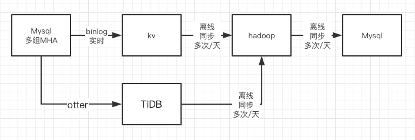
增加此链路之后,跟踪发现TiDB同步出来的数据比kv链路同步出来数据要完整,也依靠对比TiDB的数据,发现了kv中数据同步的问题,篇幅所限不再详述。
总结
此问题解决过程中,时间非常紧迫,方案讨论、测试、上线在3天之内完成,可以说是完全凭着对p厂的信赖,硬着头皮上的。结果不错,自从冗余链路上线后,基本没有了数据问题,老板们和项目的同事也都比较满意。