

【是否原创】是
【首发渠道】TiDB 社区
【正文】
说到TiDB的监控,大家第一时间想到的就是 Prometheus 和 Grafana,这两个已经是非常成熟的监控产品了,相信大家都有一定的了解。那么这里对于 Prometheus 和 Grafana 不做过多的介绍,大概就是 Prometheus 会收集 TiDB 集群信息,Grafana 会调用这些信息生成可视化图标来进行展示。
而作为一名 DBA,为 TiDB 集群保驾护航之时,就少不了这两大工具,无论是日常巡检还是问题排查,我们都需要打开 Grafana 看看集群状态,研究各种指标,一一排查问题所在。
本文主要介绍一次实际项目中的 Prometheus 使用和踩的一些坑,那是真的是坑!如果你尝试对 TiDB 的Prometheus 进自定义开发或是对接其他监控告警系统等,那么读完这篇文章会对你有很大的帮助!
项目背景
首先谈谈项目背景,这次项目主要是搭建了一套TiDB的集群,节点非常多,然后对于TiDB集群的监控,公司有自己的要求,因为整个公司不止有一套 TiDB 集群,还有其他的 MySQL,Oracle 集群,为了方便公司的数据库管理,对于所有的数据库集群的监控和告警都希望集成到同一个监控平台和告警平台。
简单的说就是开发了一套自有的监控和告警平台,来管理所有的数据库集群,那么对于 TiDB 集群,我们的设计是,仍然使用 TiDB 自带的 Prometheus 作为集群信息的收集者,然后在自有的监控告警平台上,通过使用PQL 来查询 Prometheus 的数据,进行展示和对接到相应的告警系统。你可以简单理解成重新开发了一个Grafana 和 AlertManage。
Prometheus集成到自定义平台
TiDB 的 Prometheus 本身就自带一系列告警规则,这些告警规则基本就涵盖了 TiDB 集群的方方面面,所以我们可以将这些告警规则直接搬过来。在 Prometheus 的部署目录,conf 文件下面可以找到。

在这些规则中,我们可以提取出自己想要的一些规则集成到咱们自己的平台上,具体的集成方法可以参考一下:
- 首先到 rule.yaml 中找到自己想要集成监控告警项(比如 TiDB_server_panic_total,含义是 TiDB Server 出现panic 错误超过一次则告警)
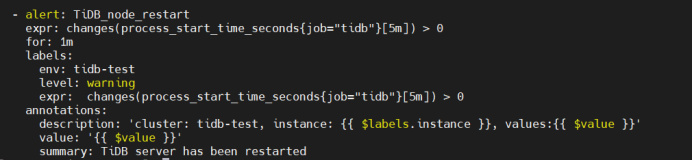
- 获取到 PQL,也就是 Expr 后面的这一段:,表达式非常容易理解,在5分钟内,如果 TiDB 进程的启动时间出现变化,就代表 TiDB 服务重启过。
- 访问 Prometheus 的 API,通过 PQL 获取到数据,访问方式就是 http://prometheus_address/api/v1/query
response = requests.get('http://%s/api/v1/query' % prometheus_address, params={'query': query})
-
获取到的查询结果后,就可以自行对结果进行处理,处理后输出到自己的监控告警平台上面。
-
对于 PQL 可以通过 http://prometheus_address/graph 先进行调试,关于PQL的语法也比较简单,只要知道相应的 TiDB 指标和 PQL 的基本函数,就可以轻松的查询想要的结果。如果你觉得比较麻烦,我建议还是直接使用rule.yaml里面的expr的表达式,然后做一些小的修改就能满足绝大部分场景。

将 Prometheus 集成到自定义监控告警系统大概就这么简单,获取结果后如何发挥,就看大家自己的业务逻辑和设计了。
一言难尽的那些坑
其实整个过程实现难度并不大,最大的难度,可能也只是在于你怎么处理从 Prometheus 获取到的数据。然而就这么简单的过程中,你也会遇到大量的坑去踩,坑的主要来源在于文档和版本。
我大致描述一下:
我们都知道 TiDB 的版本更新是非常快的,所以对于 TiDB 的一些监控指标会随着版本发生变化,但是,TiDB版本的更新速度和监控规则相关代码的跟新速度是不一样的,这里就出现了两个变化因素,这个时候,我们就需要查询各种文档,来进行统一,比如TiDB 集群报警规则 | PingCAP Docs,问题又来了,TiDB告警的文档更新的更慢,并且存在一些问题,这个时候你是不是就傻眼了?
当有三个因素都在变化的时候,想要确认某一件事情可谓是纠结万分,例如我举一个列子
tikv_batch_request_snapshot_nums 这个指标。

在文档中,这个指标意思是某个TiKV 的 Coprocessor CPU 使用率超过了 90%,但是当你如果去掉超过 90% 的条件,单纯想要获取到 Coprocessor CPU 使用率的时候,你会发现 PQL 无法从 Prometheus 中查询到任何的数据。
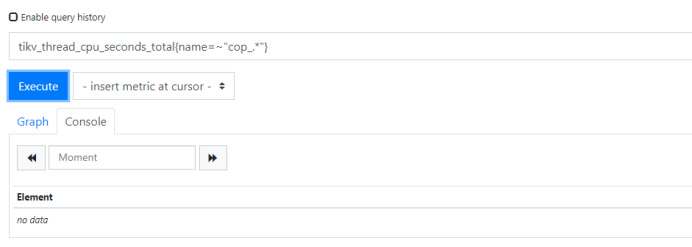
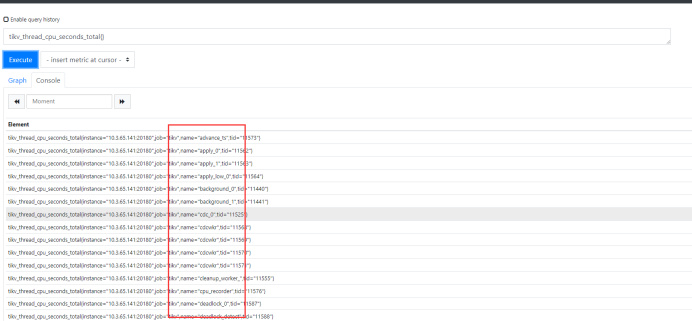
原因很简单,因为该PQL中 tikv_thread_cpu_seconds_total 这个指标里面根本就没有 name 为 cop 开头的,也就是你无法通过这个指标获取到 Coprocessor 的 CPU 使用率,而且不仅仅是文档,就连 Prometheus 里面 rule.yaml 也出现了同样的错误,所以在某些版本TiDB集群里的Grafana中你会发现你的 Coprocessor CPU 面板是没有数据的,如下:
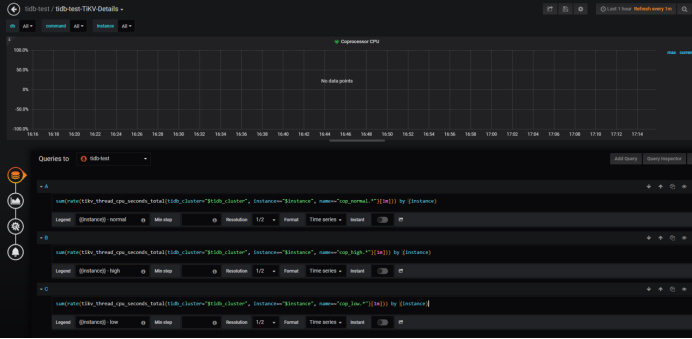
那么根本原因是什么?我分析的是因为在TiDB新版本中,引入了 UnifyReadPool 的概念,也就是将Coprocessor 线程池与 Storage Read Pool 合并起来,那么 Coprocessor CPU 的使用率指标也就同样放到了 UnifyReadPool 里面去了,不在做单独的监控指标。
当然,有问题的监控指标还有很多,比如一些弃用了的指标,还有一些改名了的指标,合并或是拆解的指标,大家在使用的过程中,一定要多进行测试,不然到时候集群出了问题,监控和告警没反应那就很危险了。
总结
由于篇幅有限,这里就不把那些有问题的地方一一呈现了,这篇文章主要是记录一次 TiDB 集群监控告警自定义设计的项目实践,帮助大家更好的掌握和使用 TiDB 的 Prometheus,其中也是遇到了一些坑,希望拿出来和大家分享,提醒大家在使用过程中注意一下。
踩了这么多坑,就会发现,TiDB 和其文档虽然现在已经是相当强大了,但却依然存在一些大大小小的问题,作为社区的一员,也是会经常遇到这些问题。而 TiDB 作为一个开源项目,我们享受开源福利的同时,其实也可以为其尽一份力,当我们发现这些问题的时候,就可以去 Github 仓库提交一个小小的 PR,帮助其完善。
之前也是发现了 Prometheus 的指标 node_cpu 在后面更新变成了 node_cpu_seconds_total,而文档还没有更新,我就提了一个 PR 到 PingCAP 的 doc 仓库,还获得了一个 Contributor 的徽章,非常滴炫酷。
