

【是否原创】 否
【首发渠道】知乎
【首发渠道链接】 TiDB SQL调优实战——索引问题 - 知乎 (zhihu.com)
【正文】
一、前言
前一阵子,迫于业务压力,将一套拥有两个多TB数据的,并且稳定运行两年多的,TiDB v2.1的集群升级到TiDB v4.0,希望能快一点,的确,升级之后,解决了大多数问题,查询速度的确比平差快了很多。但是有些业务还是没有太大改善。决定单独将那些SQL单独拿出来做一些优化,看看问题出在哪。
这里我就拿两个比较典型的SQL语句来说明一下,两条都是与索引息息相关的SQL。
二、例子
-
问题SQL 1
SELECT
a.SOID ID,
a.SA,
a.SB,
SUM( a.AMOUNT ) AMOUNT,
SUM( a.BM ) BM
FROM
(
SELECT
haso.SOID,
haso.SA,
haso.SB,
SUM( hpar.A_M ) AMOUNT,
SUM( hpar.A_BM ) BM
FROM
HPAR hpar
INNER JOIN
HASO haso ON hpar.SOID = haso.SOID
AND haso.WO_STATUS = 'P'
AND hpar.DISPLAY_FLAG = 'Y'
GROUP BY
haso.SOID
UNION ALL
SELECT
haso.SOID,
haso.SA,
haso.SB,
SUM( hpar.TARGET_AM ) AMOUNT,
SUM( hpar.TARGET_A_BM ) BM
FROM
HPAR hpar
INNER JOIN
HASO haso ON hpar.TARGET_SOID = haso.SOID
AND haso.WO_STATUS = 'P'
AND hpar.DISPLAY_FLAG = 'Y'
GROUP BY
haso.SOID
) a
GROUP BY
a.SOID;
这条SQL语句是业务系统启动时的脚本SQL,其中hasr这张表在这两年多的时间积累里面,已经有两亿条数据,hapo也有将近两亿的数据。随着时间的推移,业务系统启动的时间也越来越长,甚至偶尔会出现超时的情况。升级集群虽然有所改善,但还是慢,于是决定单独将这条SQL拿出来跑。真是不跑不知道,一跑吓一跳,平均查询耗时600s,最长甚至跑了1000多s才跑出结果。

问题SQL 1排查过程
当时排查这个问题的时候,决定将这种长的还包含union all 的SQL语句拆开,从子查询开始入手,一段一段的拆开优化。
于是,针对这段子查询,explain analyze查看其执行计划。
EXPLAIN ANALYZE SELECT
haso.SOID,
haso.SA,
haso.SB,
SUM( hpar.A_M ) AMOUNT,
SUM( hpar.A_BM ) BM
FROM
HPAR hpar
INNER JOIN
HASO haso ON hpar.SOID = haso.SOID
AND haso.WO_STATUS = 'P'
AND hpar.DISPLAY_FLAG = 'Y'
GROUP BY
haso.SOID
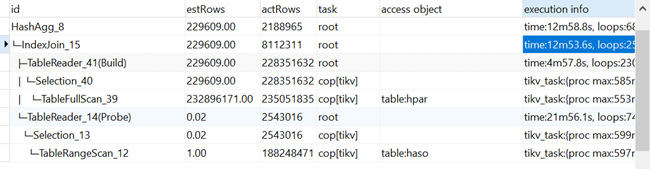
能够发现,罪魁祸首出在扫描表hpar的时候,走的是TableFullScan,全表扫描数据,扫了两亿多行的数据,大大的拖慢了整个SQL的执行时间。那么问题来了,为什么走的是TableFullScan呢?因为不论是hpar的 SOID字段还是DISPLAY_FLAG字段均建立了索引,但从上面的执行计划上来看,是没有命中索引。
问题SQL 1解决办法
没有命中索引,第一时间想到的就是统计信息的缺失,于是决定排查统计信息,通过 show stats_healthy 查看该表的健康度,发现健康度只有54。果不其然,表健康度太低,统计信息不全,导致索引失效,带来的结果就是在查询时并没有命中索引,走的是TableFullScan,全表扫描,耗费大量的时间以及资源。最后运行 analyze HPAR 刷新统计信息,问题得以解决。将所有涉及到的表统计信息全都刷新了一遍之后,该条SQL最终的运行速度稳定在40s以内,有了显著提升。
-
问题SQL 2
SELECT
DATE_FORMAT(a.A_DATE,'%Y-%m-%d'),
a.COMPANY_NAME,
a.CHANNEL_NAME,
a.DEPARTMENT_NAME,
a.ITEM_CODE,
a.BARCODE,
a.ITEM_NAME,
IF('ITEM' = a.BUSINESS_UNIT,'单品','礼包'),
a.INVOICE_TYPE,
a.INVOICE_CODE,
a.SPECS,
IF('N' = a.OUT_FLAG,'否','是'),
CONCAT(a.FIRST_CLASS,'.',a.SECOND_CLASS,'.',a.THIRD_CLASS),
a.THIRD_CLASS,
a.TAX_RATE,
a.PRODUCT_NUMBER,
SUM(
cast(
a.SETTLE_QUANTITY AS DECIMAL ( 18, 2 ))),
a.ACCOUNT_NAME,
SUM(
cast(
a.INPUT_AMOUNT AS DECIMAL ( 18, 2 ))),
SUM(
cast(
a.SETTLE_AMOUNT AS DECIMAL ( 18, 2 ))),
SUM(
cast(
a.TAX_AMOUNT AS DECIMAL ( 18, 2 )))
FROM
(
SELECT
haso.SIGN_COMPANY,
haso.DEPARTMENT_CODE,
haso.SETTLE_MODEL,
haso.SETTLE_ORDER_ID,
hpssv.DESCRIPTION AS COMPANY_NAME,
hpssv2.DESCRIPTION AS CHANNEL_NAME,
hpssv3.DESCRIPTION AS DEPARTMENT_NAME,
haso.A_DATE AS A_DATE,
haso.BUSINESS_UNIT,
hasoL.PRODUCT_NUMBER,
hasoL.SETTLE_AMOUNT AS SETTLE_AMOUNT,
hasoL.TAX_AMOUNT AS TAX_AMOUNT,
hasoL.SETTLE_QUANTITY AS SETTLE_QUANTITY,
hasoL.INPUT_AMOUNT AS INPUT_AMOUNT,
tpii.ITEM_CODE,
tpii.BARCODE,
tpii.DESCRIPTION AS ITEM_NAME,
tpii.INVOICE_TYPE,
tpii.SPECS,
tpii.OUT_FLAG,
tpii.FIRST_CLASS,
tpii.SECOND_CLASS,
tpii.THIRD_CLASS,
tpii.TAX_RATE,
tpii.INVOICE_CODE,
hpssv4.DESCRIPTION AS ACCOUNT_NAME,
tpicm.ACCOUNT_CODE
FROM
HASO haso
LEFT JOIN HASOL hasoL ON haso.SETTLE_ORDER_ID = hasoL.SETTLE_ORDER_ID
LEFT JOIN TPII tpii ON hasoL.PRODUCT_NUMBER = tpii.ITEM_CODE
LEFT JOIN TPICM tpicm ON tpii.FIRST_CLASS = tpicm.FIRST_CLASS
AND tpii.SECOND_CLASS = tpicm.SECOND_CLASS
AND tpii.THIRD_CLASS = tpicm.THIRD_CLASS
LEFT JOIN HPSSV hpssv ON haso.SIGN_COMPANY = hpssv.SEGMENT_VALUE
AND hpssv.TYPE_CODE = 'COM'
LEFT JOIN HPSSV hpssv2 ON haso.SETTLE_MODEL = hpssv2.SEGMENT_VALUE
AND hpssv2.TYPE_CODE = 'CHANNEL'
LEFT JOIN HPSSV hpssv3 ON haso.DEPARTMENT_CODE = hpssv3.SEGMENT_VALUE
AND hpssv3.TYPE_CODE = 'DEPT'
LEFT JOIN HPSSV hpssv4 ON tpicm.ACCOUNT_CODE = hpssv4.SEGMENT_VALUE
WHERE
haso.A_DATE >= '2020-10-01 00:00:00'
AND haso.A_DATE <= '2020-10-27 23:59:59'
AND haso.SIGN_COMPANY in ('3001')
AND haso.BUSINESS_UNIT IN ( 'ITEM', 'BAG' )
UNION ALL
SELECT
haso.SIGN_COMPANY,
haso.DEPARTMENT_CODE,
haso.SETTLE_MODEL,
haso.SETTLE_ORDER_ID,
hpssv.DESCRIPTION AS COMPANY_NAME,
hpssv2.DESCRIPTION AS CHANNEL_NAME,
hpssv3.DESCRIPTION AS DEPARTMENT_NAME,
haso.REVERSE_ACCOUNT_DATE AS A_DATE,
haso.BUSINESS_UNIT,
hasoL.PRODUCT_NUMBER,
- hasoL.SETTLE_AMOUNT AS SETTLE_AMOUNT,
- hasoL.TAX_AMOUNT AS TAX_AMOUNT,
- hasoL.SETTLE_QUANTITY AS SETTLE_QUANTITY,
- hasoL.INPUT_AMOUNT AS INPUT_AMOUNT,
tpii.ITEM_CODE,
tpii.BARCODE,
tpii.DESCRIPTION AS ITEM_NAME,
tpii.INVOICE_TYPE,
tpii.SPECS,
tpii.OUT_FLAG,
tpii.FIRST_CLASS,
tpii.SECOND_CLASS,
tpii.THIRD_CLASS,
tpii.TAX_RATE,
tpii.INVOICE_CODE,
hpssv4.DESCRIPTION AS ACCOUNT_NAME,
tpicm.ACCOUNT_CODE
FROM
HASO haso
LEFT JOIN HASOL hasoL ON haso.SETTLE_ORDER_ID = hasoL.SETTLE_ORDER_ID
LEFT JOIN TPII tpii ON hasoL.PRODUCT_NUMBER = tpii.ITEM_CODE
LEFT JOIN TPICM tpicm ON tpii.FIRST_CLASS = tpicm.FIRST_CLASS
AND tpii.SECOND_CLASS = tpicm.SECOND_CLASS
AND tpii.THIRD_CLASS = tpicm.THIRD_CLASS
LEFT JOIN HPSSV hpssv ON haso.SIGN_COMPANY = hpssv.SEGMENT_VALUE
AND hpssv.TYPE_CODE = 'COM'
LEFT JOIN HPSSV hpssv2 ON haso.SETTLE_MODEL = hpssv2.SEGMENT_VALUE
AND hpssv2.TYPE_CODE = 'CHANNEL'
LEFT JOIN HPSSV hpssv3 ON haso.DEPARTMENT_CODE = hpssv3.SEGMENT_VALUE
AND hpssv3.TYPE_CODE = 'DEPT'
LEFT JOIN HPSSV hpssv4 ON tpicm.ACCOUNT_CODE = hpssv4.SEGMENT_VALUE
WHERE
REVERSE_ACCOUNT_DATE IS NOT NULL
AND haso.REVERSE_ACCOUNT_DATE >= '2020-10-01 00:00:00'
AND haso.REVERSE_ACCOUNT_DATE <= '2020-10-27 23:59:59'
AND haso.SIGN_COMPANY in ('3001')
AND haso.BUSINESS_UNIT IN ( 'ITEM', 'BAG' )
) a
GROUP BY
a.SIGN_COMPANY,
a.DEPARTMENT_CODE,
a.SETTLE_MODEL,
a.A_DATE,
a.PRODUCT_NUMBER,
a.BUSINESS_UNIT,
SIGN(
a.SETTLE_AMOUNT
)
这条SQL语句,问题比上一个要更严重,因为压根儿就跑不出结果,跑了五六千秒还能继续跑,也不报错,继续在那跑,欸,就很离谱。由于是在navicat中运行的,后面只能通过show processlist 以及 kill tidb ‘processID’ 来终止查询。
问题SQL 2排查过程
同样的,基于上一条SQL的基本思路,将这个长SQL拆开来看,先用explain analyze看子查询的执行计划。跑的这个SQL涉及到haso、tpii、hpssv、hasol、tpicm五张表。其中,hpssv、tpii、tpicm表都不大,均只有两万多条数据,但是haso有接近两亿条数据,hasol有两千多万条。
EXPLAIN ANALYZE SELECT
haso.SIGN_COMPANY,
haso.DEPARTMENT_CODE,
haso.SETTLE_MODEL,
haso.SETTLE_ORDER_ID,
hpssv.DESCRIPTION AS COMPANY_NAME,
hpssv2.DESCRIPTION AS CHANNEL_NAME,
hpssv3.DESCRIPTION AS DEPARTMENT_NAME,
haso.A_DATE AS A_DATE,
haso.BUSINESS_UNIT,
hasoL.PRODUCT_NUMBER,
hasoL.SETTLE_AMOUNT AS SETTLE_AMOUNT,
hasoL.TAX_AMOUNT AS TAX_AMOUNT,
hasoL.SETTLE_QUANTITY AS SETTLE_QUANTITY,
hasoL.INPUT_AMOUNT AS INPUT_AMOUNT,
tpii.ITEM_CODE,
tpii.BARCODE,
tpii.DESCRIPTION AS ITEM_NAME,
tpii.INVOICE_TYPE,
tpii.SPECS,
tpii.OUT_FLAG,
tpii.FIRST_CLASS,
tpii.SECOND_CLASS,
tpii.THIRD_CLASS,
tpii.TAX_RATE,
tpii.INVOICE_CODE,
hpssv4.DESCRIPTION AS ACCOUNT_NAME,
tpicm.ACCOUNT_CODE
FROM
HASO haso
LEFT JOIN HASOL hasoL ON haso.SETTLE_ORDER_ID = hasoL.SETTLE_ORDER_ID
LEFT JOIN TPII tpii ON hasoL.PRODUCT_NUMBER = tpii.ITEM_CODE
LEFT JOIN TPICM tpicm ON tpii.FIRST_CLASS = tpicm.FIRST_CLASS
AND tpii.SECOND_CLASS = tpicm.SECOND_CLASS
AND tpii.THIRD_CLASS = tpicm.THIRD_CLASS
LEFT JOIN HPSSV hpssv ON haso.SIGN_COMPANY = hpssv.SEGMENT_VALUE
AND hpssv.TYPE_CODE = 'COM'
LEFT JOIN HPSSV hpssv2 ON haso.SETTLE_MODEL = hpssv2.SEGMENT_VALUE
AND hpssv2.TYPE_CODE = 'CHANNEL'
LEFT JOIN HPSSV hpssv3 ON haso.DEPARTMENT_CODE = hpssv3.SEGMENT_VALUE
AND hpssv3.TYPE_CODE = 'DEPT'
LEFT JOIN HPSSV hpssv4 ON tpicm.ACCOUNT_CODE = hpssv4.SEGMENT_VALUE
WHERE
haso.A_DATE >= '2020-10-01 00:00:00'
AND haso.A_DATE <= '2020-10-27 23:59:59'
AND haso.SIGN_COMPANY in ('3001')
AND haso.BUSINESS_UNIT IN ( 'ITEM', 'BAG' )
然后,就遇到一个问题,发现这个子查询也同样跑几千秒跑不出结果,无奈之下,只能结合 show processlist与explain for connection ‘processID’ 来查看正在跑的这段SQL的执行计划。
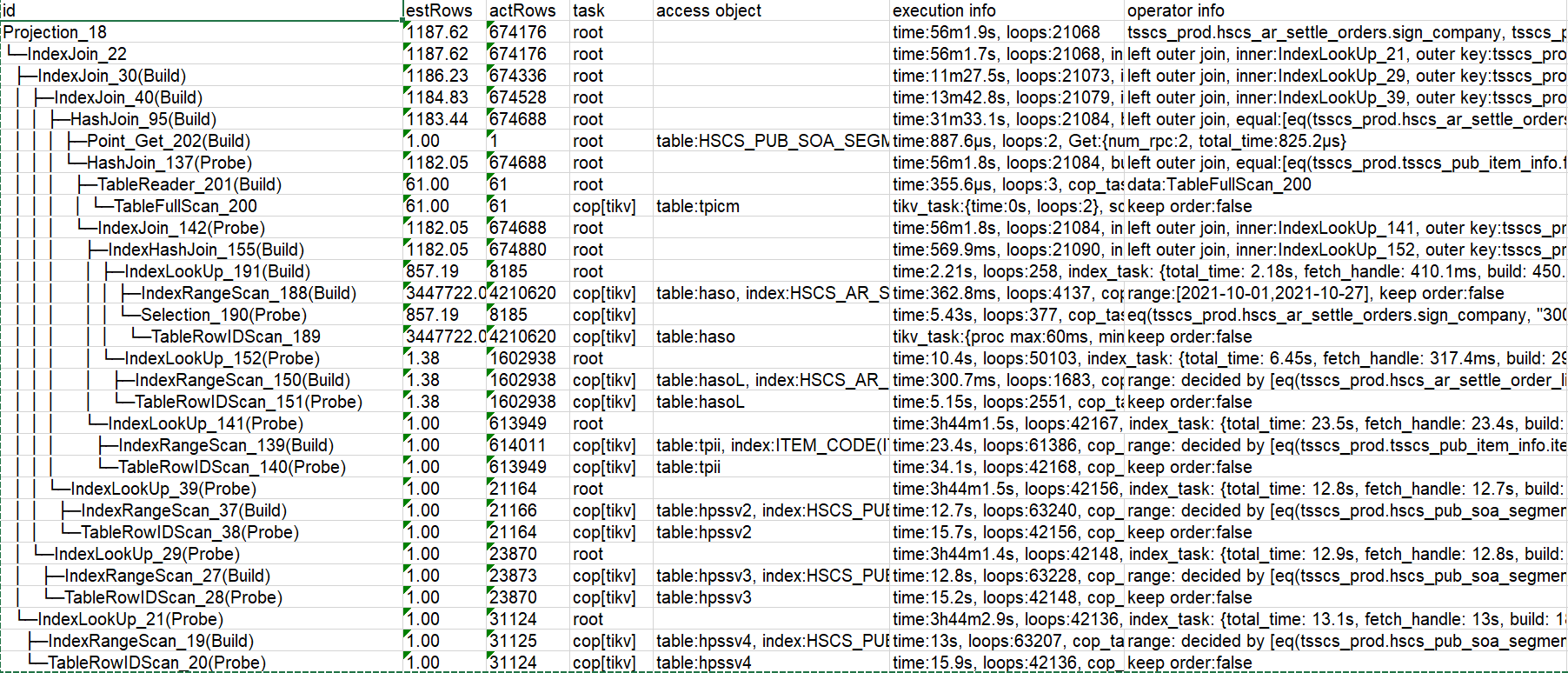
其实,从这个执行计划中我们能够发现,问题就出在最后的四个表的扫描上。

这四个表的扫描走的均是IndexLookUpReader,也就是说使用了索引的方式来扫描表中数据,但是四个表,扫描的时长,着实显得非常的不合理。没办法,一张表一张表的来看吧。先看tpii,前面提到过,这个表的数据只有两万多,但是使用ITEM_CODE这个索引扫描,花了很长的时间还没扫描结束。于是展开execution Info查看执行的详细信息,发现对于一个两万多数据的表,读这个表的时候扫了63W+的keys,接近64W。

看来问题终于是找到了,扫描的key太多,以至于SQL执行不成功,甚至都不能执行出结果。到了这里,不禁反问自己,为什么会扫描这么多的key呢?
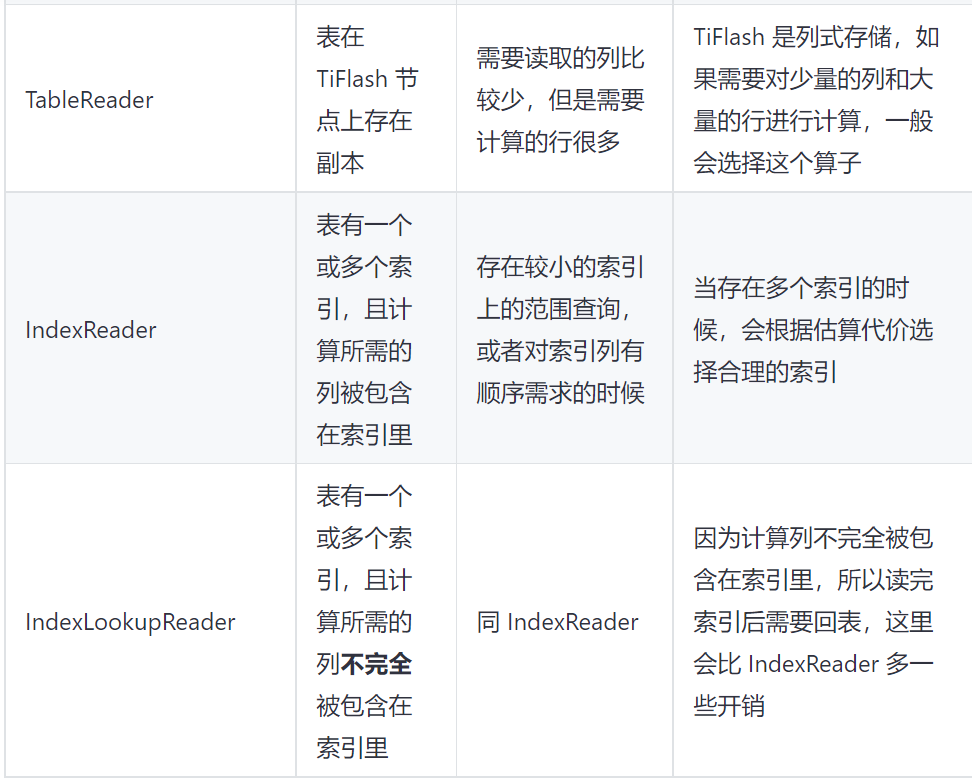
看上面TiDB官方文档关于其部分索引算子的一些解释。在最开始的执行计划里面,能看到扫描tpii这张表,用的是IndexLookUpReader,比一般的IndexReader多了一步回表操作。那么很明显,在扫表时,错误的使用ITEM_CODE索引,导致做了没有必要的回表步骤,导致最后扫表的key的数量超出了认知,更拖慢了SQL查询的时间。
问题SQL 2解决办法
使用hint,在子查询 select后面添加 /*+ IGNORE_INDEX() */的hint
SELECT /*+ IGNORE_INDEX(tpii,ITEM_CODE)*/
...
同样的,使用 /*+ IGNORE_INDEX() */的hint 来忽视 hpssv这四张表用到的索引,将hpssv、tpii的执行计划由原来的IndexLookUpReader改变陈TableFullScan,这样一来,SQL的运行速度比之前快了几十倍不止,稳定之后,平均执行时间只有10s不到,相比以前,要快了100倍。
三、总结
从这次SQL调优中,影射出很多系统中关于不当使用TiDB的问题。
但是话又说回来了,毕竟这是一个两年前的系统,当年开发这套系统的人都已经离职了,也许当时数据量不大,集群压力小,并且对于TiDB的了解也仅仅止步于 高度兼容MySQL5.7协议的分布式数据库,对于后面的这种问题也不会考虑到这么全面,写出来的SQL语句当时能跑,并且能稳定的跑出结果,就烧高香,万事大吉了,哪还管身后洪水滔天的,再加上平时也缺乏专门的数据库运维人员,对于这方面也缺乏重视,所以出现类似于今天SQL调优的这种问题也见怪不怪了。
很多人明明有了汽车,却用马拉着车,自己躺在车里面,气愤于别人骑着摩托车超过自己,最后赖这汽车不行。TiDB是一个很好的产品,但是怎么正确的,遵循TiDB原理的去使用这款产品,也显得尤为重要。
在AskTug中,TiDB 数据库开发规范 - 技术文章 - AskTUG,这篇文章推荐读一读,关于使用TiDB数据库的一些东西讲的挺好的,我也受益颇多。