【是否原创】是
【首发渠道】TiDB 社区,转载请注明出处
背景介绍
TiSpark 是 PingCAP 为解决用户复杂 OLAP 需求而推出的产品。它借助 Spark 平台,同时融合 TiKV 分布式集群的优势,和 TiDB 一起为用户一站式解决 HTAP (Hybrid Transactional/Analytical Processing) 的需求。TiSpark 依赖于 TiKV 集群和 Placement Driver (PD),也需要搭建一个 Spark 集群。
其架构图如下:

作者前一段时间做过TiSpark on k8s的实践,请参考:https://asktug.com/t/topic/422775/3。
实践过程中,通过Spark ui可以观察到,TiSpark写入过程中,做了很多的工作,如下所示:
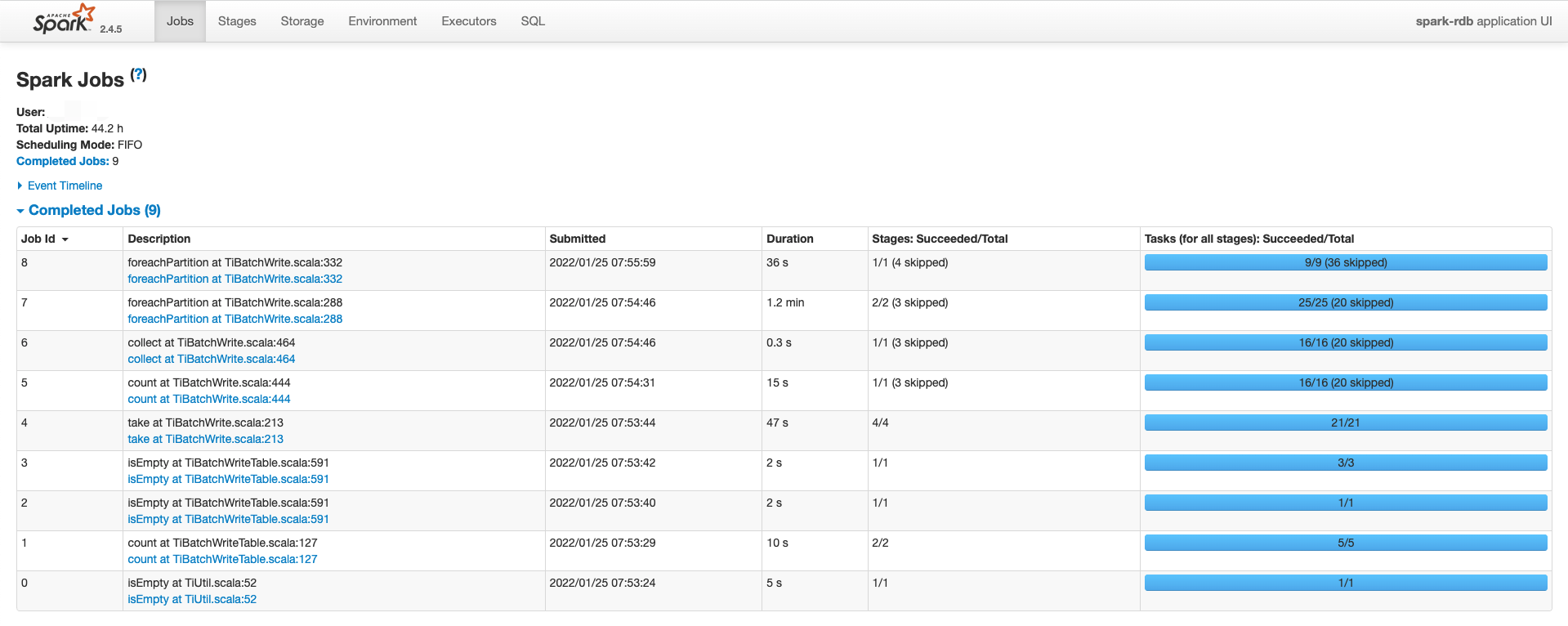
结合执行过程,充分理解官方文档后,大约理解这个过程是把写数据,拆分region等动作,都用Spark进行了处理,然后直接写入tikv。那么具体都干了哪些事情?顺序是怎样的?下面通过阅读源码来讲解。
阅读版本:TiSpark-2.4.1
源码分析
整体流程介绍
整体流程图如下:

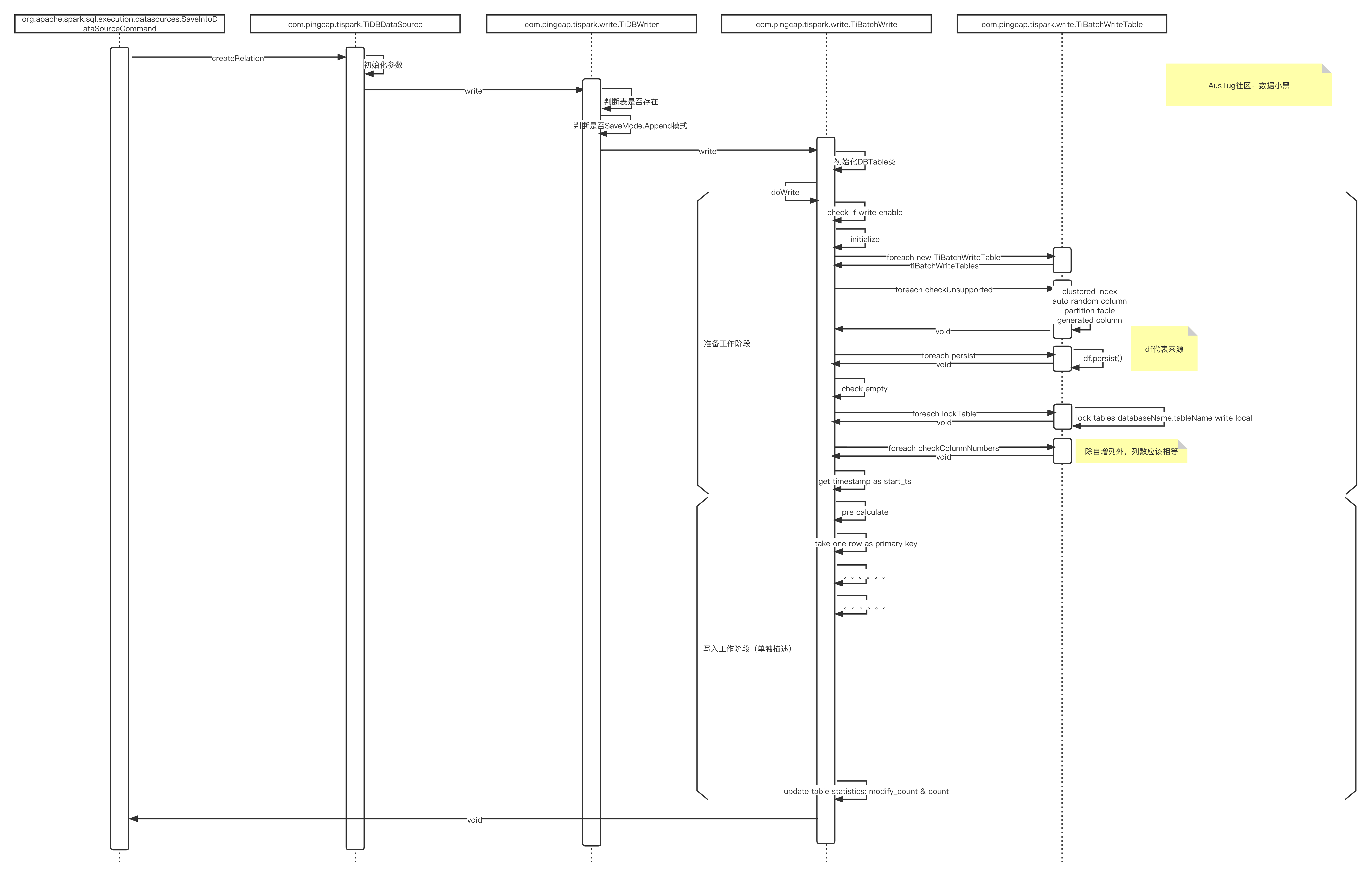
从上述流程图可以看到,整个过程大体分了5个步骤:
- 初始化与检查:初始化批写类,检查来源表与目标表是否符合要求
- 数据预处理:根据目标表的要求,对来源数据进行检查和补充
- 预分区(Region)与打散分区(Region):对数据进行预分区与打散分区操作,此处分区是指的region
- 两阶段提交:通过两阶段提交过程,提交数据
- 刷新统计信息:刷新表的统计信息
下面对前四个阶段的内容做详细分析。
初始化与检查
在Spark中执行save方法后,Spark会调用org.apache.spark.sql.execution.datasources.SaveIntoDataSourceCommand的run的方法,Spark实例化com.pingcap.tispark.TiDBDataSource之后,会执行TiDBDataSource的createRelation方法,然后执行整个写入过程。

主要的几个类的分工如下:
com.pingcap.tispark.write.TiBatchWrite:逻辑控制
com.pingcap.tispark.write.TiBatchWriteTable:每个写入过程实例化一个TiBatchWriteTable,过程中操作的具体实现类
初始化与检查进行了如下工作:
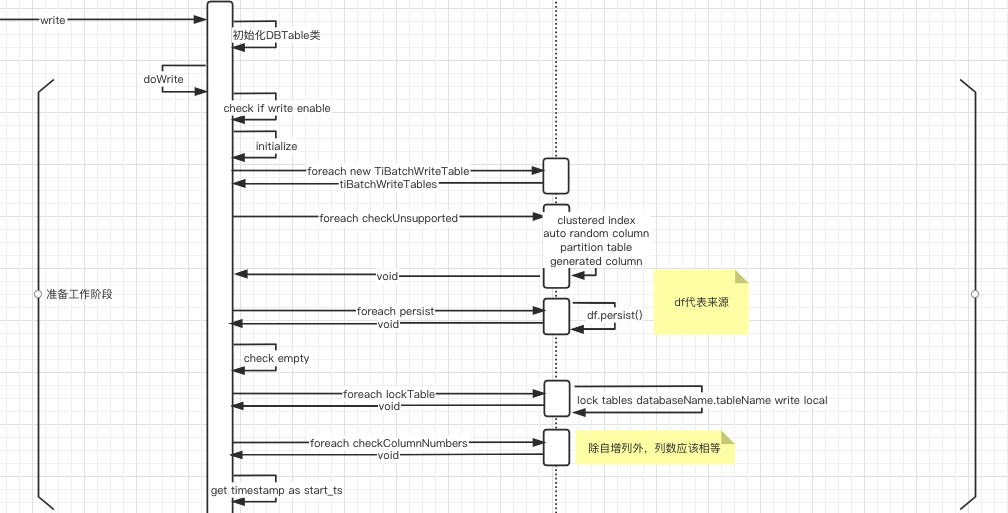
图中,左边的是TiBatchWrite,右边的是TiBatchWriteTable。
在这个阶段,主要做了一些类的初始化;一些参数的检查 :是否开启了批写开关spark.tispark.write.enable,
是否属于下列不支持的情况之一:clustered index,auto random column,partition table,generated column;表的检查:列的数据量是否一致,来源表是否是空表。
这个阶段最后,对目标表进行了加锁处理:lock tables databaseName.tableName write local
数据预处理
数据预处理阶段工作如下:

此阶段主要进行了三个动作:
- 自增列处理:如果自增列全部为空值,则直接删除,如果自增列有值,则删除原有自增列的值,重新填充
- spark row到tikv row的转化:转化spark的row为tikv的row,转化后的row对象组成的rdd用于后续数据写入
- 构建最终写入数据集:根据主键或者唯一索引的状况,构建最终数据集,包含无主键冲突的insert数据和有主键冲突的replace数据
预分区(Region)与打散分区(Region)
预分区(Region)与打散分区(Region)阶段动作如下:
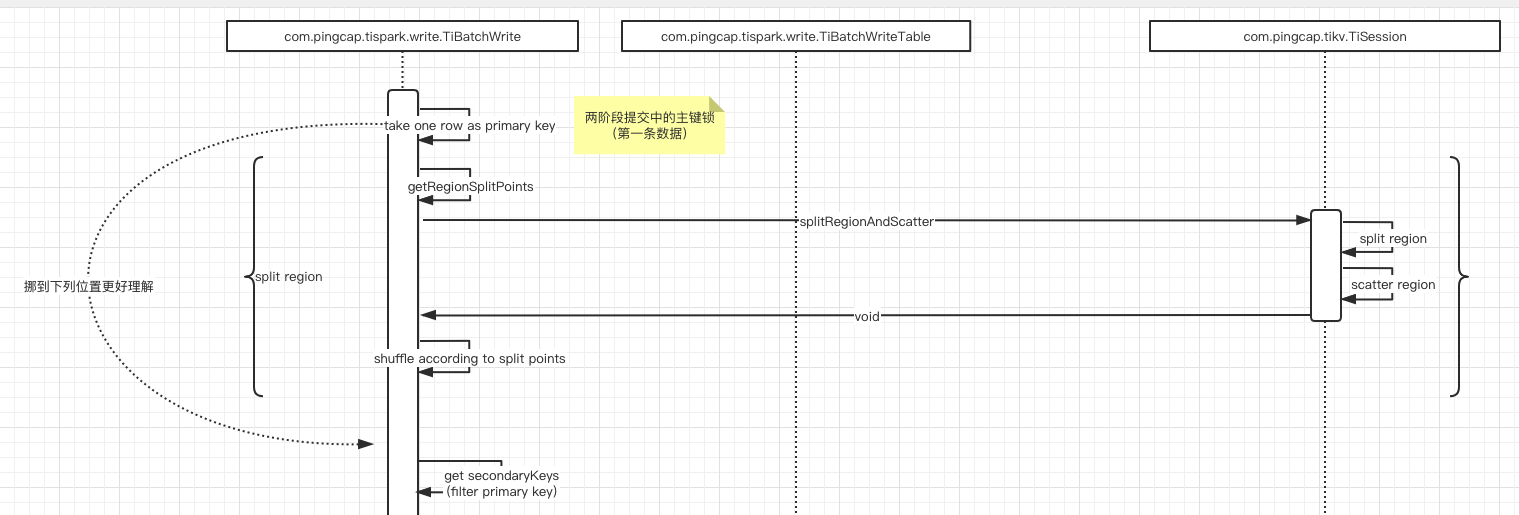
此阶段的主要动作是调用com.pingcap.tikv.TiSession,根据当前数据情况,对数据进行split region和scatter region,此阶段执行完之后,数据对应的region已经在tikv上创建,并在节点直接打散。
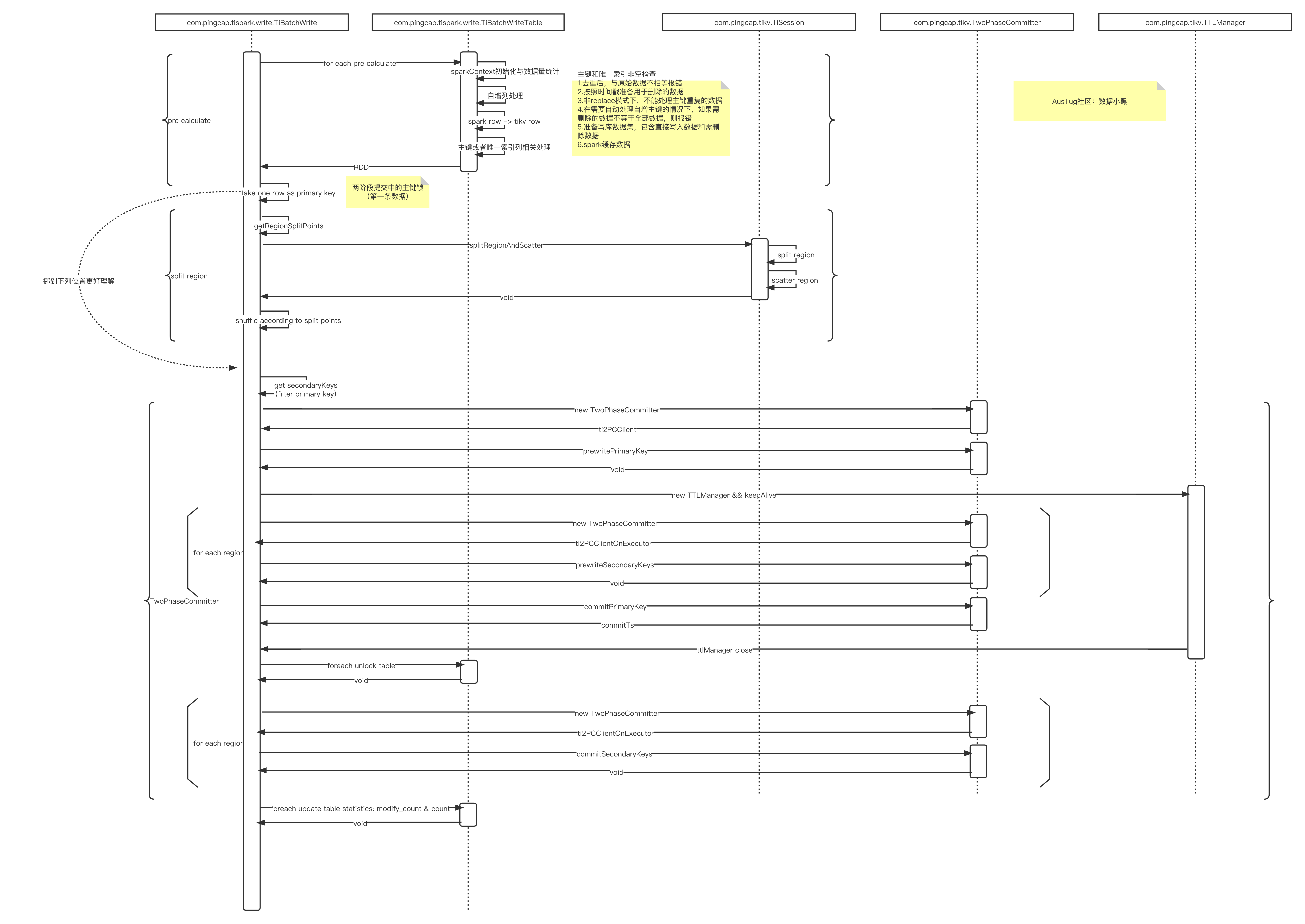
两阶段提交
两阶段提交的工作如下:
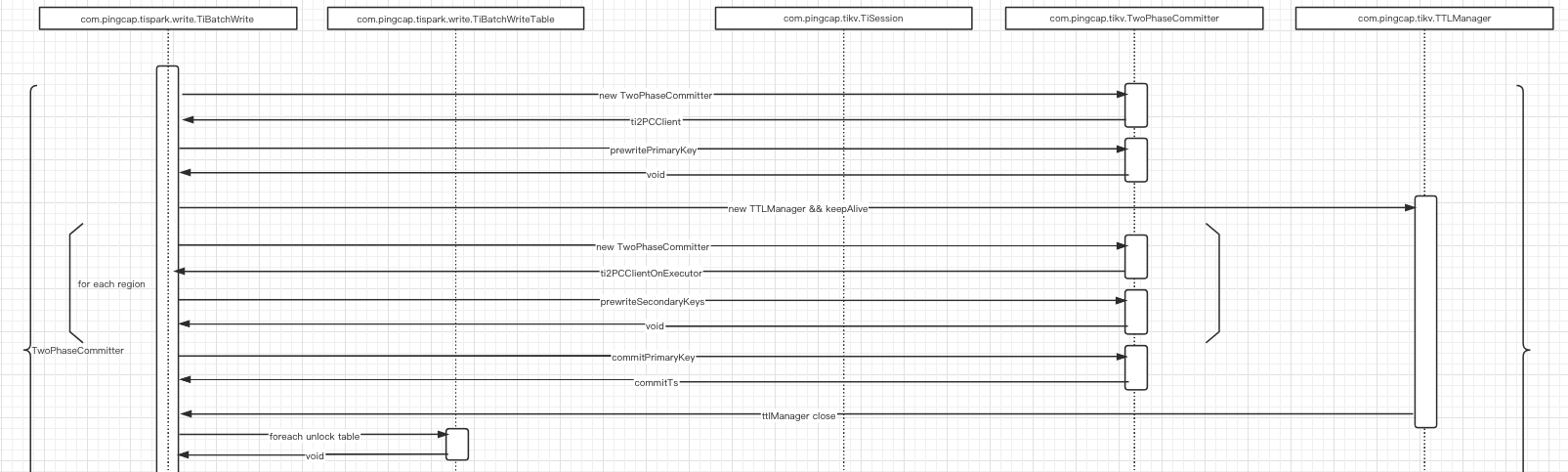

分了几个过程:
- prewritePrimaryKey
- prewriteSecondaryKeys
- commitPrimaryKey
- unlock table
- commitSecondaryKeys
整个过程的理解可以参考:https://pingcap.com/zh/blog/percolator-and-txn,作者水平有限,怕写不好引起误解,在此不再赘述。
其他资源
文末附上时序图,因作者水平有限,如果有理解不对的地方,请指正。