

【是否原创】是
【首发渠道】TiDB 社区
【首发渠道链接】其他平台首发请附上对应链接
【正文】
首先分库分表不是一个最优的解决方案。做过数据库的朋友应该知道关系型数据库有ACID的四大要素。其中一致性,尤其是强一致性是和NoSQL的区别之一。我们通常说一个计算机如何厉害,会说这是军用级别,因为要求高。而数据库最高的级别不是军事级别,而是金融级别。金融级别对一致性的要求可以说是苛刻的。通常关系型数据库在单机或者集群下比如Oracle的RAC就是强一致性的。因为在一个数据库或者集群下是数据库利用事务来保证一致性的。而多个独立的数据库(分库)是无法保障的。
我们举例而说:有的系统原来是一个Oracle库,运行稳定。随着微服务和中台概念出现,采用了将数据库分成几十个数据库来建设。比如会员、订单、合同、结算、资金等等。
分库的痛点:
当订单发生改变的条件下,单机和分库的处理差别是这样的(订单变了和订单强依赖的一系列必然会发生连锁变化,是非常合理的):
在原始Oracle中,在一个事务中订单表发起变更,同步更新了合同表、资金表和会员表最终的余额。如果遇到超时或者锁定异常则回退,重新再次执行。
在分库的系统中,需要更新订单数据库,合同数据库、资金数据库和会员数据库。如果采用同步方案系,统之间的调用时间不可控制,效率低下。如果采用异步的方案,每个数据库独立工作,一旦一个没有写成功,那么整个环节和流程上都存在了不一致的问题。以哪个为准?
分表的痛点:
无论用什么维度对表进行切分,那么意味着如果不按照这个维度查询,那么必然要遍历所有表才能得到结果。比如一般按照userid进行分表,查询一个userid的所有订单,是没有问题的。
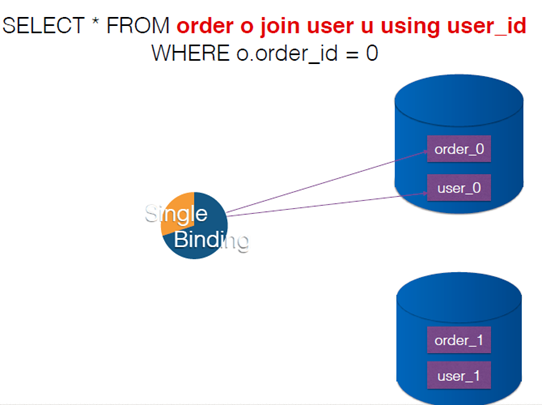
但是如果查询当天所有数据库的订单,要遍历所有数据库去查。
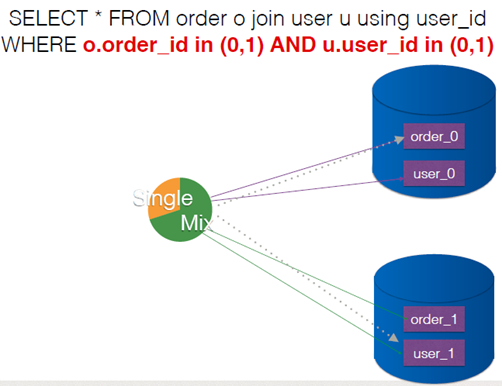
不仅如此,数据还涉及到合并和排序(数据合并好理解,为什么要排序?)

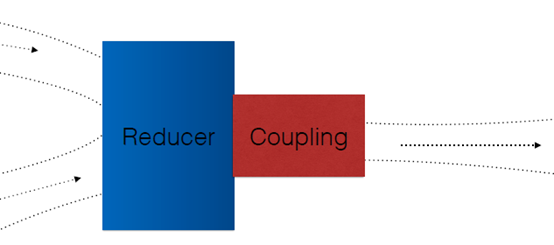
那是因为一般用户都是希望拿到的数据是有序的,即使数据库不自带,也要考虑到应用开发的SQL会带Order by的输入。
这里就引申出另外一个问题,分库分表是不是分布式数据库?答案是否定的。只有支持分布式事务才是分布式数据库。
TiDB设计之处就秉承了云原生的分布式数据库。TiDB是一个不需要分库分表的MySQL。而云原生是说产品是依托于云可以发挥出弹性优势,为了云而设计的,在云的场景下发挥的最好。
在学习TiDB的过程,其实可以发现一个不用分库分表的数据库才是解决问题的根本。因为当分库分表以后带来的问题非常大,大到我不愿意去分甚至宁可不分。在亿级别的数据库场景下,B-tree的层级最多也就3-4层。即使冷数据4次IO也可以找到数据,无需分库分表完成。所以没有分库分表的分布式数据库才是解决问题的王道。
OLAP 的痛点
什么是分析?用简练的话来说就是对少量列的聚合。如果说在数据库里面有几条数据,请问你觉得应该是下面这种形式存储的吗?一行从A到J是一条数据,一共13行。而我们只要统计蓝色的C列。
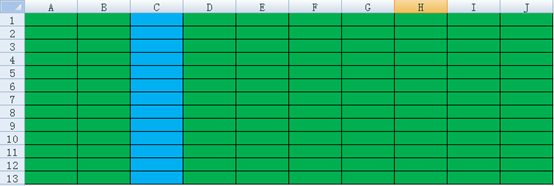
图1
还是像下图一样的存储?一种颜色代表一行,收尾相连的存储?

图2
以上两个图都是用excel表达。可能大多数人一开始都觉得是第一个excel。因为她就是一个excel。但是实际上看过图2的人基本会否定图1.图2才是数据库真实存储的样子。所以即使统计C的sum,也要把各个颜色(每条记录)遍历一下才能得到结果。所以列越长,行越多的表统计分析就越慢。而我们熟悉的excel是在内存中进行列的统计,而且数据量不大才显得快。
关系型数据库是行存的,而分析系统是列存比较有优势。怎么才能做到HATP既能满足交易又能满足分析。答案只有一个就是行列混存。
Oracle采用了磁盘行存,内存列存的方式解决。而TiKV是行存,TiFLash列存。
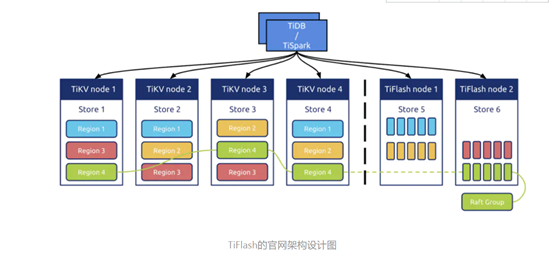
虽然做的方式方法不一样,但是原理大致一样。在MySQL的HeatWave也是类似的实现原理。

这张图引用黄东旭老师一次分享的图片。
当你真的做过把Oracle和MySQL的数据往CDH中送的项目就知道,坑实在太多了。首先ETL解决不了实时问题,其次Hive不支持修改,HBase不支持关联。对于源端数据的update和delete来说,Hive处理非常复杂。
HATP的意义就在于对应用透明,不再需要hadoop生态圈的十几种技术栈来完成BI、数仓和报表,大大节约了企业设备成本、人力成本。