

**作者介绍:**田维繁,网易游戏资深数据库工程师,TUG 华南区 Co-Leader。数据库老兵,维护过多种数据库,目前在网易游戏负责数据库私有云平台的运维和开发。
在 TUG 网易线上企业行活动中,来自网易游戏的资深数据库工程师田维繁老师分享了 TiDB 海量 region 集群调优主题 ,以下内容整理自当天活动分享实录。
此次分享的主题包括三个方面:
- 第一部分是关于网易游戏以及网易游戏目前使用 TiDB 现状;
- 第二部分是 tombstone key 案例分享,包括整个排查过程介绍;
- 第三部分是使用 TiDB 5.0 的初体验以及未来展望。
一、关于我们
我们是面向整个网易游戏,提供一站式数据库私有云服务的部门,提供包括 MongoDB、MySQL、Redis、TiDB 等数据库服务。网易云 99% 以上的游戏业务都在使用我们提供的数据库私有云服务。

TiDB 在网易游戏的使用情况如下:整个 TiDB 的集群数量在 50+,TiDB 环境的整体数据规模在 200TB+,最大的集群节点数 25+,包括大部分的 TiKV 以及小部分的 TiFlash 节点,单集群的最大数据量在 25TB+。尽管目前 TiDB 属于初步使用阶段,但是也已经达到了一定规模,整个业务使用过程中我们也碰到了诸多问题。
本次分享我挑选了一个比较有意思的案例,分享我们排查的整个过程,也非常期望大家能从中得到一定的参考借鉴。
二、tombstone key 引发的“血案”
我们分享的案例是 tomstone key 引发的“血案”,可能有的小伙伴们会问 tomstone key 是什么?后面会详细的介绍 tomstone key 的含义。

为什么叫“血案”呢?是因为一想到血案,大家会觉得这个问题确实比较严重。
这个问题当时影响了网易某大型游戏的实时和离线业务分析场景,导致整个分析业务不可用,进而影响了内部数据报表系统的可用性。另外,由于持续时间还较长,游戏的产品运营以及公司的高层也无法及时地看到游戏数据。
2.1 背景
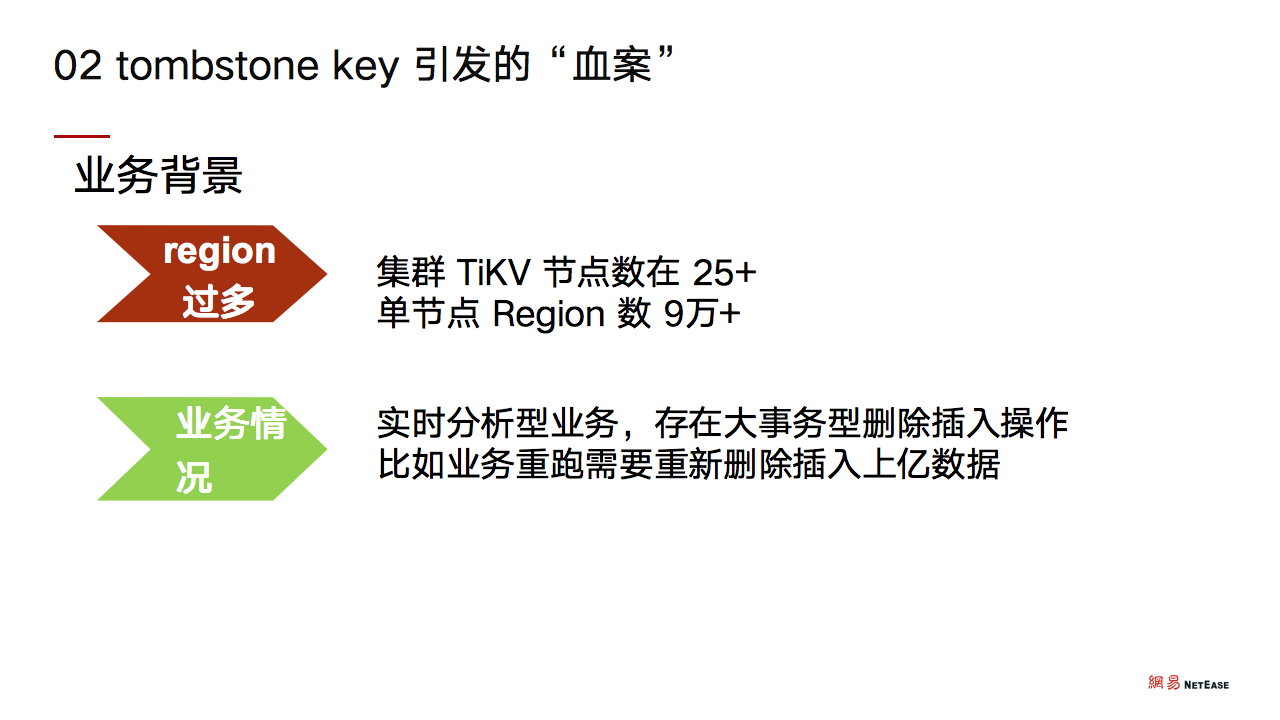
在分析具体问题前,先简单介绍一下整个业务背景:集群单节点 region 数非常多,TiKV 节点数在 25+,单节点 region 数在 9 万+。主要业务属于实时分析型的业务,存在大量的事务型删除和插入操作。
2.2 问题现状
下面进入问题案例现场,这个案例从一个电话报警开始。某一天凌晨 4 点,我们接到了电话报警,确定问题影响之后,第一时间通知业务,然后开始问题排查,看看到底是什么引起的报警。
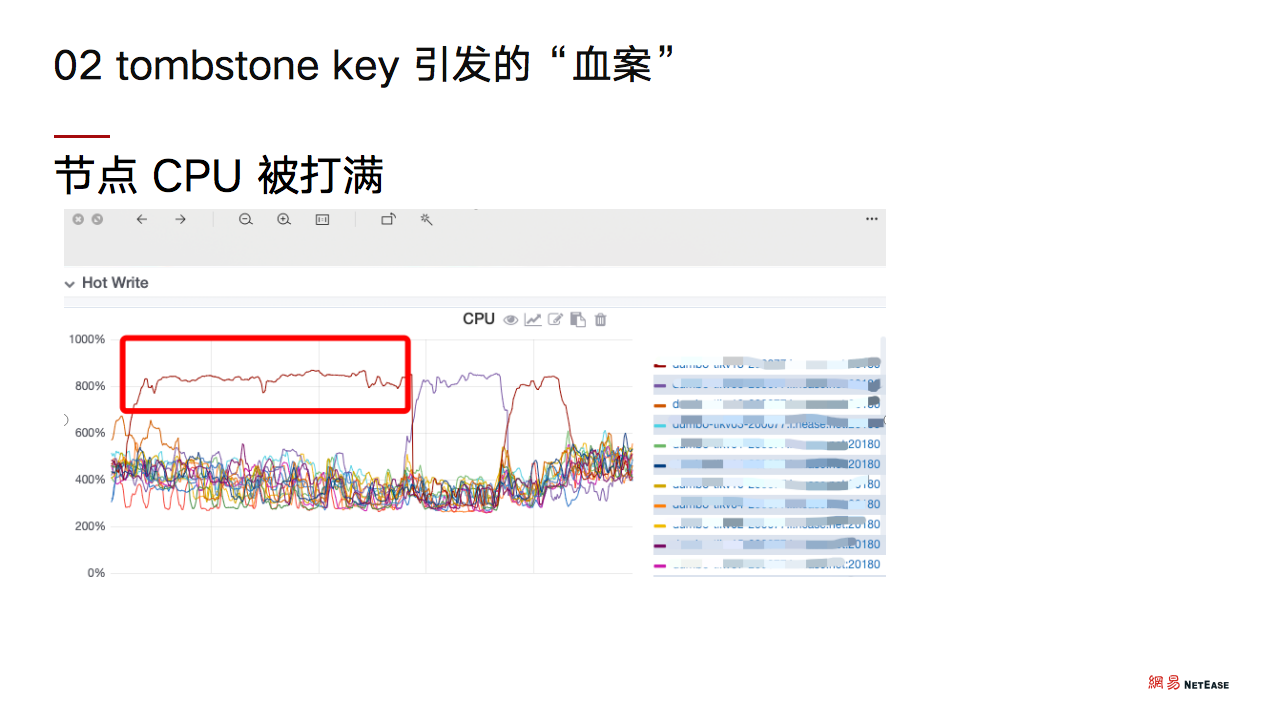
如上图所示,可以看到整个节点的 CPU 是被打满的,此时首先猜测是否因为热点导致了这种现象,一般情况下单个节点 CPU 异常高,都会被认定为是热点问题。为了快速处理这个问题,我们暂时先把该节点下线,以免导致整个数据库的不可用。
结果发现将该节点下线之后,其他的 TiKV 节点也会突然出现飙高的情况,即不能通过简单的重启节点来让业务恢复正常。既然是热点问题,那么紧急排查热点刻不容缓。
首先,热力图确实存在一些热点问题,可以有针对性的找出热点对应的一些表。

其次,通过热力图,以及一些热点的元数据表,锁定大批量的热点表,发现这些表都是联合组建的。
这样就比较简单了,直接批量设置一个参数 SHARD_ROW_ID_BITS 去打散。

同时,也需要联系业务去发现可能存在的热点表,一起做打散。
除此之外,我们还会监控 hot region 表,如果出现未打散的表,会设置参数自动打散。并且适当调整 PD 的热点调度并发数,然后加大整个热点的调度,可以快速处理类似的热点问题。经过一波调整之后,发现 CPU 确实降下来了,访问业务反馈也正常,仿佛问题已经解决了。
但是到了第二天,我们在 10 点钟又收到一波的电话报警,此时的问题在业务上已经十分紧急,我们立即对整个问题进行重新梳理。
梳理过程中,我们回顾了第一次处理的情况,猜测要么第一次处理问题不够彻底,要么根本就不是热点问题导致的。
于是我们回归问题本身进行分析。既然是 CPU 飙高,我们首先从 CPU 这个点去排查,排查完之后发现是 storeage readpool CPU 这项指标飙高。

这个指标飙高之前其实没有碰到过,当时也比较迷茫,所以我们联系了 TiDB 社区的技术专家:启斌、启航以及跃跃,在线支持。
通过日志,以及一些其他的指标:包括 seek duration 以及 Batch Get 等,锁定了是 seek tombstone key 引起的问题。
回到最开始的问题,什么是 tombstone key ? 这里也简单介绍一下。

一般删完数据之后,TiDB 中会保留多版本数据,即在新插入数据覆盖老数据时,老数据不会马上被清理掉,而是和新数据一起保留,同时以时间戳来区分多版本。
这些多版本数据什么时候被删除清理掉呢?
此时有一个 GC 线程,GC 线程会通过后台去遍历,遍历超过 GC 时间的一些 key 。然后将这些 key 标记为 tombstone key。这些 key 其实只是做一个标记,即所谓的 tombstone key。这些 key 的清理是由 RocksDB 引擎后台发起一个线程以 Compaction 的方式来进行回收。
RocksDB 整个 Compaction 过程这里也简单介绍一下。
首先数据插入 RocksDB 之后,会写入 WAL,然后正式的写入 memory table 的内存块。当内存块写满之后,我们会把它标记为 immutable member table。
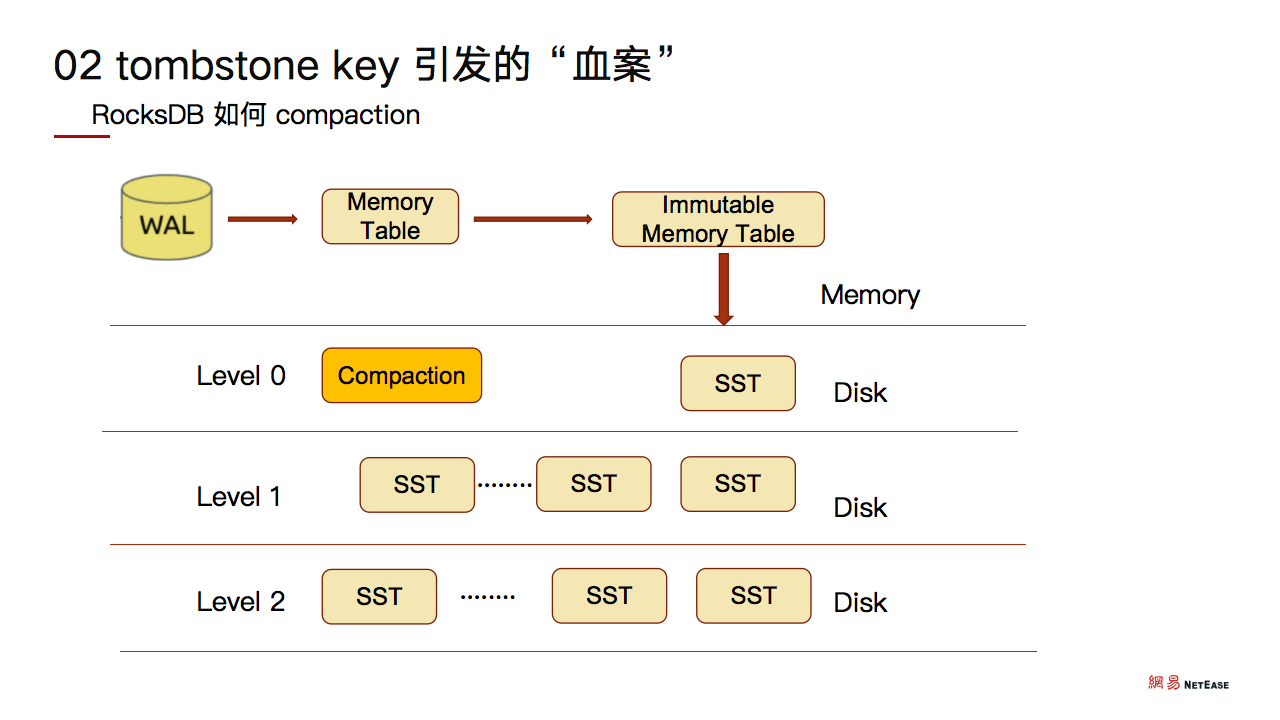
标记完之后,RocksDB 会把内存块 flush 到磁盘,生成一个 SST 文件,这就是我们的所谓的 level 0 层。
当 level 0 层 SST 文件越来越多时,就会出现大量的重复数据,也即 tombstone key 会开始出现在这一层,此时 RocksDB 就会通过 compaction 的方式,将这些 SST 合并到 level 1 层。
当 level 1 层文件达到一定预值之后,又会合并到 level 2 层,这就是整个 RocksDB compaction 过程的简单描述。
到这里,整个问题几乎确认了原因。

故障发生前业务删除过大量的数据,也即在存在大量 tombstone key。在这种情况下执行大量事务,TiKV 就可能会 seek 到大量的被删掉的 tombstone key。由于需要跳过这些 tombstone key,所以可能会导致 batch get 的性能严重下降,进而影响整个 Storage ReadPool CPU 飙高,使整个节点卡住。
这里需要回顾一下,第一次处理问题的时候,我们通过热点打散之后,整个问题仿佛就恢复了?
为什么当时我们热点打散之后问题就恢复了?其实我们也做一个回顾,当时发现在打散热点的时候,确实对整个问题有了一定的缓解,最根本原因在于处理的过程中,RocksDB 对底层的 tombstone key 做了一个 compaction,导致 tombstone key 消失了,所以问题得到了恢复。
确定问题之后,下一步就是怎么样去优化,彻底解决这个问题。为此,我们制定了一些优化的措施。
2.3 如何优化
- 业务侧

首先,分区表改造。某些场景如:业务在补数据时可以按天直接删除分区,TiDB 就会走快速的 Delete Ranges 而不用等 compaction。
其次,避免热点问题。业务读请求改为 follower read 方式,创建表指定打散特性,缓解读写热点问题,一定程度上缓解了 seek tombstone key 的影响。
第三,尽可能拆分大事务。事务过大,对整个 TiKV 层,都会造成比较大压力;事务过大时,需要操作大量的 key,更容易触发 tombstone key。
在业务层做一些优化方案之后,在运维侧我们也去做了一些处理的方案或者优化的方案。
- 运维侧
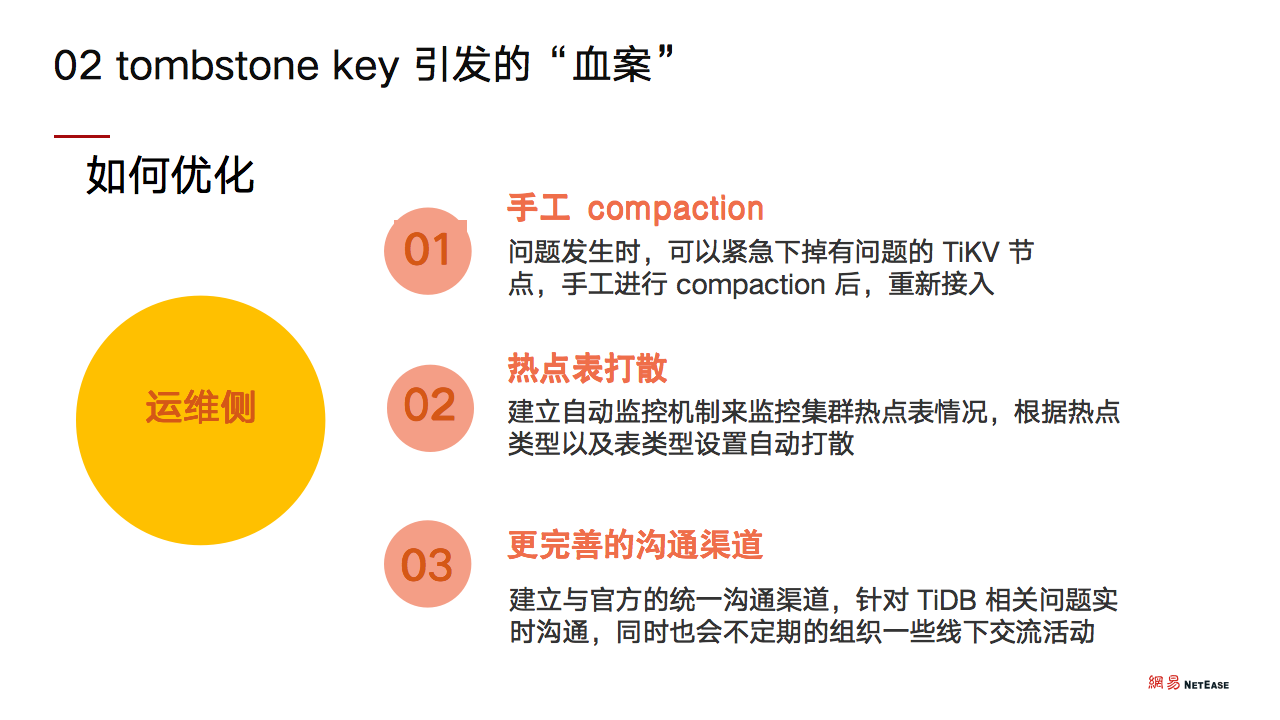
首先,手工 compaction。问题发生时,可以紧急下掉有问题的 TiKV 节点,手工进行 compaction 后,重新接入。
其次,热点表打散。建立自动监控机制来监控集群热点表情况,根据热点类型以及表类型设置自动打散。
第三,更完善的沟通渠道。建立与官方的统一沟通渠道,针对 TiDB 相关问题实时沟通,同时也会不定期的组织一些线下交流活动。
- 彻底优化思路
其实这个问题最好的方案是从数据库层做一个彻底的优化,从上述介绍中,思路应该是比较明了的。

存在 tombstone key 的场景下,写操作或者是 Batch Get,只要绕过这些 tombstone key 从而避免 seek 过多的 tombstone key,就可以很彻底地避免这个问题。此外,相关的优化方案,官方已经合并到了 TiDB 5.0,并且在 4.0.12 版本也做了一个优化。
三、TiDB 5.0 初体验
我们非常期待 5.0 的到来。所以在 5.0 发布之后也第一时间做了一些相关测试。这里针对一些测试案例,简单地跟小伙伴们分享一下。
3.1 TiDB 5.0 测试体验
- 稳定性

首先是稳定性,因为我们是 4.0 或者 4.0 之前的版本,或多或少都会碰到一些问题,比如在高并发的情况下出现性能抖动,这个问题也一直困扰着我们,我们在测试的时候发现 TiDB 4.0.12,在高并发情况下,整个 duration 还有 QPS 都是有一定的波动的。
通过对比测试 5.0,发现整个 duration 和 QPS 是比较稳定的,甚至几乎看到是一条稳定的直线。
- MPP
5.0 也开发了一些新特性,我们对一些新特性比较感兴趣,所以也做了一些测试。
比如两阶段提交,可以看到在测试过程中打开异步提交之后,整体的插入性能 TPS 提升了 33%,延时响应降低了 37%,相较之前有比较大的提升。
提到 5.0,不得不提到一个 5.0 特性的重头戏,也就是 MPP 特性,这也是我们比较关注的。
对此,我们做了很多的测试,包括基准测试和一些其他的单 SQL 测试。
这里我想跟大家分享一个真实的数据库场景测试案例。测试的 MySQL 大概有 6T 的数据,我们跟 TiDB 5.0 的 MPP 做了性能对比,结果发现 MPP 在 5.0 单个 TiFlash 情况下,大多数时候比 MySQL 的性能好并且很多,甚至有些会比 MySQL 性能好十几倍。

如果有多个 TiFlash ,在使用 MPP 特性之后,性能会更佳。通过测试,我们对 5.0 充满了信心。
3.2 TiDB 5.0 未来可期
接下来我们会去推动 5.0 的落地,比如一些实时业务分析的场景,同时也会主推一些大数据场景在 TiDB 5.0 的落地。除此之外,推进 TP 型的业务在 TiKV 5.0 的落地也在我们的计划之中。

对于整个数据库的私有云服务而言,我们在整个 TiDB 建设过程中,做了很多周边的生态,比如数据库迁移、统一监控平台,还有一些自动化的创建、添加等等。
后续我们会继续完善整个 TiDB 的生态建设,使 TiDB 能更好的在整个网易游戏的云服务落地,同时解决我们业务的后顾之忧。
在使用过程中,我们也得到了 TUG 小伙伴们的大力支持。所以我们在获取 TUG 社区支持的同时,也会去深度参与整个 TUG 社区的建设,共建整个 TUG 社区。
? 更多 TiDB、TiKV、TiSpark、TiFlash 等技术问题可登录 AskTUG.com ,与全球 TiDB User 随时随地交流使用心得~ 另外,AskTUG 「认证功能」最新上线,完成团队认证可额外获得 +200 经验值和 200 积分 ,授予 “认证会员”徽章。更有问题处理「加急」特权等你~详情了解请点击「阅读原文」!
阅读原文链接:
 【已结束】完成认证抽“周边三件套”,解锁“加急”处理问题权限 功能上新
【已结束】完成认证抽“周边三件套”,解锁“加急”处理问题权限 功能上新
为了可以给 TiDB 社区 的小伙伴提供更加好的体验, 我们开通认证入口啦~ 大家赶紧来完成认证:https://tidb.io/account/organization/new 获得**“加急**”处理问题权限,加快问题响应速度 完成团队认证,可以获得 +200 经验值,+200 积分 , 并授予 “认证会员” 徽章 也可以获得以下【试运行权益】: 1、团队空间 2、“加急” 处…
关于 TUG
TUG(TiDB User Group) 是由 TiDB 用户自发组织、管理的独立社区,PingCAP 官方提供赞助与支持。目前共有华北、华东、华南(广州、深圳)、西南(成都、重庆)、TUG APEC(新加坡)小组。TUG 成立的初衷是“连接用户,共建社区”,汇聚了全球数据库、大数据技术从业者,是一个独立、自发、不以盈利为目的的组织。
如果你对数据库、大数据感兴趣,如果你也想跟业界大咖们一起交流最前沿的数据库与大数据知识,欢迎加入 TUG,和 TUG 一起成长!

扫码加入 TUG