

【是否原创】是
【首发渠道】TiDB 社区
【首发渠道链接】其他平台首发请附上对应链接
【正文】
1. 概述
两地三中心架构,即生产数据中心、同城灾备中心、异地灾备中心的高可用容灾方案。在这种模式下,两个城市的三个数据中心互联互通,如果一个数据中心发生故障或灾难,其他数据中心可以正常运行并对关键业务或全部业务实现接管。相比同城多中心方案,两地三中心具有跨城级高可用能力,可以应对城市级自然灾害。
TiDB 分布式数据库通过 Raft 算法原生支持两地三中心架构的建设,并保证数据库集群数据的一致性和高可用性。而且因同城数据中心网络延迟相对较小,可以把业务流量同时派发到同城两个数据中心,并通过控制 Region Leader 和 PD Leader 分布实现同城数据中心共同负载业务流量的设计。
2. 系统架构
为更接近真实环境本验证方案使用北京、西安两地的机房进行部署,其中西安机房中使用2个网段IP模拟2个不同的IDC机房,全部为ARM CPU,北京机房全部为x86 CPU ,共同组建成两地三中心架构,在此架构中任何一个机房出现故障都不会影响对外提供服务,如果同城的两个中心同时故障则 在异地灾备中心进行故障恢复,然后提供服务,因为异步传输、网络延迟等情况可能会出现数据丢失情况。
通过对tikv存储节点设置具有层级关系的label可让TiDB具备机房、机架、主机的物理位置感知能力,比如层级关系设置为city、zone、rack、host,在机房、机架、主机数量充足时,tidb能保障同一主机不会有相同副本、同一机架内不会相同副本,且根据中心数量进行分散。本次验证方案设计label为[‘city’,’zone’,’host’],整体部署结构如图:
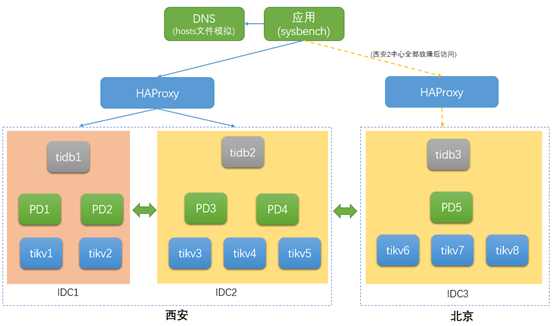
正常时为保障性能防止读写请求会发送到灾备中心机房,因此将灾备中心上的副本leader全部驱逐到西安2个中心。西安双中心同时对外提供服务,所有副本的leader运行于此。北京中心作为异地灾备中心与西安双中心网络延迟较高,经实际测试延迟在20ms左右,且由一定波动。
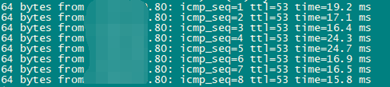
通过/etc/hosts文件设置多个相同主机名条目,分别指向北京和西安的负载均衡HAProxy,模拟DNS功能,当西安双中心故障后注释该中心对于IP。
3. 系统优化
注 : 本方案验证并非性能测试仅对以下参数进行了调整,数据库仅分配6G内存且整个集群、表结构未进行任何调整优化。
消息压缩传输
设置参数server.grpc-compression-type: gzip 开启TiKV gRPC 消息压缩传输,降低跨机房间的网络传输
调整 PD balance 容忍度
设置参数schedule.tolerant-size-ratio: 20.0,当两个 store 的 leader 或 Region 的得分差距小于指定倍数的 Region size 时,PD 会认为此时 balance 达到均衡状态。
延迟选举
在北京灾备中心tikv设置参数,拉长灾备中心参与raft leader选举时,尽量避免参与选举。
raftstore.raft-min-election-timeout-ticks: 1000
raftstore.raft-max-election-timeout-ticks: 1200
设置副本数量
config set max-replicas 5
驱逐灾备中心leader
可以使用evict-leader调度器或placement-rules进行驱逐,本次验证使用evict-leaer方式,使用placement-rules配置时注意设置group的override否则会和默认的rule叠加导致副本数超预期。
pd-ctl scheduler add evict-leader-scheduler 1
调整PD 优先级
调整pd优先级使pd leader仅在西安双中心内选举产生pd leader
member leader_priority PD-10 5
4. 验证内容
4.1 两地三中心性能验证
不驱逐北京灾备中心leader情况下,使用sysbench分别进行5分钟的oltp_select_points、oltp_insert、oltp_delete测试, 验证2地3中心的全部tikv提供服务时2个城市的网络延迟对系统性能影响。
驱逐北京灾备中心leader仅西安2个中心提供服务,使用sysbench分别进行5分钟的oltp_select_points、oltp_insert、oltp_delete测试。
预期结果:仅西安2个中心提供服务时的性能要好于两地三中心同时提供服务。
4.2 任一中心故障后服务可用性验证
使用sysbench进行128线程压测(oltp_select_points),压测期间使用mv重命名所有相关文件(pd、tidb、tikv)模拟该机房整体故障
由于sysbench无自动重试机制遇到错误会退出整个进程,因此停止一个中心后会导致sysbench退出,需手动再次执行sysbench,以模拟应用重试。
预期结果:
A.停止一个中心后sysbench退出 。
B.重新执行sysbench不报错,TPS 会降低。
C.整个过程可通过tidb server CPU监控反应
4.3 异地灾备恢复验证
使用sysbench(oltp_read_write)进行128线程读写压测,使用mv重命名所有相关文件(pd、tidb、tikv、haproxy),模拟西安同城2个中心完全故障,然后对北京灾备中心进行多副本失败恢复。
由于sysbench无自动重试机制遇到错误会退出整个进程,因此停止2个中心后会导致sysbench退出,需手动再次执行sysbench,以模拟应用重试。
预期结果:
关闭西安2中心后sysbench退出,再次启动不成功。
在灾备中心进行多副本失败恢复后,sysbench启动成功,TPS降低。
5. 验证结果
5.1 两地三中心性能验证
2地3中心tikv同时提供服务时leader分布
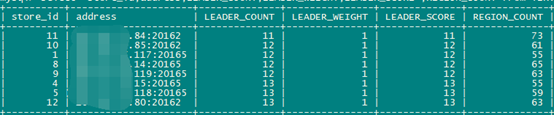
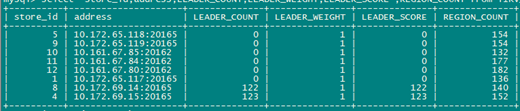
仅西安同城2中心提供服务时leader分布
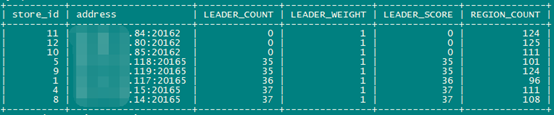
Sysbench测试对比:
| oltp_select | oltp_delete | oltp_insert | |
|---|---|---|---|
| 3中心 | 20335.55 | 16407.19 | 13072.86 |
| 2中心 | 107691.16 | 76555.21 | 18631.39 |
5.2 任一中心故障后服务可用性验证
模拟西安IDC2中心故障后集群状态
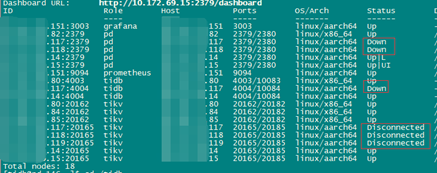
sysbench退出,TPS在11万左右

Leader分布状态。
此时西安IDC1中心只有2个tikv,同一主机有多个region副本。
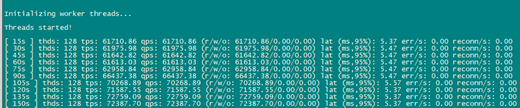
4、 重新启动sysbench无报错,由于tidb、tikv数量减少TPS在7万左右
5、检查tidb server CPU (每中心1个tidb server)
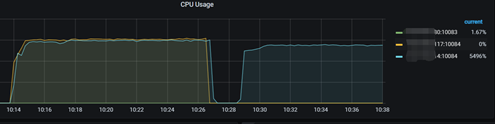
10:14 开始压测,通过DNS将流量转发至西安2个中心的tidb server,北京灾备中心无流量(绿色线)。
10:26分左右停止西安IDC2中心, sysbench退出后所有tidb server无流量。
10:28分左右重启启动sysbench,由于流量仅发往西安中心且IDC2中心完全故障,因此仅流量全部发往西安IDC1中心
5.3 异地灾备恢复验证
模拟故障后集群状态
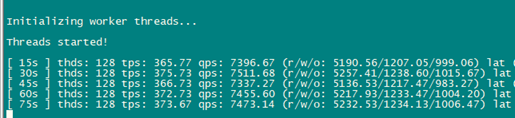
3关闭西安2个中心sysbench退出,qps在7.4万

重新启动sysbench报错

北京灾备中心进行多版本失败恢复
PD、tikv 多副本相关失败恢复操作可在TUG内搜索相关字。
(1) 从pd、tidb、tikv日志或监控中找到cluster-id和alloc-id
(2) PD多副本失败恢复
tiup pd-recover --endpoints http://10.161.67.82:2379 -cluster-id 7033562212132084087 -alloc-id 20000
(3)tikv多副本失败恢复
每个存活tikv主机执行:
tikv-ctl --data-dir /data/dr_tidb/tidb-data/tikv-20162 unsafe -recover remove -fail-stores -s 1,2,3,4,8 --all-regions
多副本恢复、剔除故障节点后集群状态

再次启动sysbench测试
此处注释/etc/hosts文件使主机名指向北京灾备HAProxy,由于北京灾备中心主机为1块普通SAS盘因此恢复后QPS、TPS均比西安2中心要低
6. 方案优缺点
该方案的优缺点如下:
优点:
利用raft原生高可用性,通过多副本功能实现强一致性,相比主从复制方案架构简单、数据一致性强。
(1) 数据副本leader位于同城的2个中心,可同时提供服务,实现同城双活功能,系统资源利用率较高。
(2) 可保证任一中心发生意外后数据不丢失、服务不中断。
缺点:
(1) 需配置5副本,数据冗余度增加,存储空间增加。
(2) 2个城市网络要求较高可能成本较高。
(3) 异地灾备仅1份副本,当同城双中心全部出现故障后,异地灾备中心需进行多副本失败恢复,服务中断,数据有丢失可能。
7. 生产环境思考
1、 需制定各场景故障下的详细应急预案及操作手册
2、 系统上线前要经过多次压力测试、切换演练测试,不断完善应急恢复脚本
3、 tiup等管理工具可使用rsync等工具配置自动同步,以在各中心都保存一份。
4、为进一步提高系统可用性,可考虑建立一套同步集群,使用TiCDC进行复制,可避免单集群故障问题,同时也可以进行容灾演练测试
5、 多副本恢复时需要cluster_id、alloc-id、store_id来恢复pd,可定时从监控数中获取并远程保存,降低恢复时获取复杂度。
6、同一中心要考虑机架、主机的分布,避免相同副本位于同一主机。
参考文档:https://docs.pingcap.com/zh/tidb/stable/three-data-centers-in-two-cities-deployment