TiDB v6.0.0(DMR) 缓存表初试
作者:啦啦啦啦啦
一、背景
一般情况下使用TiDB单表大小为千万级别以上在业务中性能最优,但是在实际业务中总是会存在小表。例如配置表对写请求很少,而对读请求的性能的要求更高。当表的数据量不大,访问又特别频繁的情况下,数据会集中在 TiKV的 一个 Region 上,形成读热点,从而影响性能,在分布式数据库中一直以来是一个痛点问题。
TiDB v6.0.0(DMR)版本推出了缓存表的功能,第一次看到这个词的时候让我想到了MySQL的内存表。MySQL内存表的表结构创建在磁盘上,数据存放在内存中。内存表的缺点很明显。当MySQL启动着的时候,表和数据都存在,当MySQL重启后,表结构存在,数据消失。TiDB的缓存表不存在这个问题。从asktug论坛中看到很多小伙伴都很期待缓存表的表现,个人也对它的性能很期待,因此在测试环境中实际看看缓存表的性能如何。
二、缓存表的使用场景
以下部分内容来自官方文档
TiDB 缓存表功能适用于以下特点的表:
- 表的数据量不大
- 只读表,或者几乎很少修改
- 表的访问很频繁,期望有更好的读性能
TiDB作为一个分布式数据库,大表的负载很容易利用分布式的特性分散到多台机器上,但当表的数据量不大,访问又特别频繁的情况下,数据通常会集中在 TiKV 的一个 Region 上,形成读热点,更容易造成性能瓶颈。因此,TiDB 缓存表的典型使用场景如下:
- 配置表,业务通过该表读取配置信息
- 金融场景中的存储汇率的表,该表不会实时更新,每天只更新一次
- 银行分行或者网点信息表,该表很少新增记录项
缓存表把整张表的数据从 TiKV 加载到 TiDB Server 中,查询时可以不通过访问TiKV直接从 TiDB Server 的缓存中读取。以配置表为例,当业务重启的瞬间,全部业务连接一起加载配置,会造成较高的数据库读延迟。如果使用了缓存表,读请求可以直接从内存中读取数据,可以有效降低读延迟。在金融场景中,业务通常会同时涉及订单表和汇率表。汇率表通常不大,表结构很少发生变化因此几乎不会有DDL,加上每天只更新一次,也非常适合使用缓存表。其他业务场景例如银行分行或者网点信息表,物流行业的城市、仓号库房号表,电商行业的地区、品类相关的字典表等等,对于这种很少新增记录项的表都是缓存表的典型使用场景。
三、集群拓扑规划
| Role | Host | Ports |
|---|---|---|
| alertmanager | 10.0.0.1 | 9093/9094 |
| grafana | 10.0.0.1 | 3000 |
| pd | 10.0.0.1 | 2379/2380 |
| pd | 10.0.0.2 | 2379/2380 |
| pd | 10.0.0.1 | 3379/3380 |
| prometheus | 10.0.0.1 | 9090/12020 |
| tidb | 10.0.0.1 | 4000/10080 |
| tidb | 10.0.0.2 | 4000/10080 |
| tikv | 10.0.0.1 | 20162/20182 |
| tikv | 10.0.0.1 | 20160/20180 |
| tikv | 10.0.0.2 | 20161/20181 |
由于硬件条件受限,只有2台普通性能的云主机混合部署的集群(实际上和单机部署也差不多了)。单机CPU核数较少且tidb server没有做负载均衡所以并发无法调整太高。以下测试均使用一个tidb server节点进行压测(贫穷限制了我的想象;´༎ຶД༎ຶ`)。因此不用特别关注本次测试的测试数据,测试结果也仅限参考。
四、性能测试
测试工具:sysbench 1.0
一.使用普通表
1.单表数据量5000,测试QPS
| 线程数 | oltp_point_select | oltp_read_only | select_random_points | select_random_ranges | oltp_read_write |
|---|---|---|---|---|---|
| 8 | 2214 | 1985 | 3190 | 2263 | 1702 |
| 16 | 3199 | 2414 | 3412 | 2491 | 1132 |
| 32 | 4454 | 2867 | 3898 | 2763 | 1101 |
| 64 | 5792 | 3712 | 4321 | 2981 | 831 |
| 128 | 7639 | 4964 | 4474 | 2965 | 686 |
2.单表数据量50000,测试QPS
| 线程数 | oltp_point_select | oltp_read_only | select_random_points | select_random_ranges | oltp_read_write |
|---|---|---|---|---|---|
| 8 | 4874 | 2808 | 2841 | 2207 | 2940 |
| 16 | 5042 | 3429 | 3172 | 2448 | 3053 |
| 32 | 6754 | 4290 | 3405 | 2651 | 3133 |
| 64 | 8989 | 5282 | 3831 | 2818 | 3294 |
| 128 | 12565 | 6470 | 3996 | 2811 | 2695 |
二.使用缓存表
1.单表数据量5000,测试QPS
| 线程数 | oltp_point_select | oltp_read_only | select_random_points | select_random_ranges | oltp_read_write |
|---|---|---|---|---|---|
| 8 | 15780 | 10811 | 5666 | 2716 | 274 |
| 16 | 23296 | 11399 | 6417 | 2948 | 330 |
| 32 | 28038 | 11313 | 6907 | 3050 | 566 |
| 64 | 32924 | 11377 | 7217 | 3200 | 435 |
| 128 | 33962 | 11413 | 7199 | 3232 | 371 |
2.单表数据量50000,测试QPS
| 线程数 | oltp_point_select | oltp_read_only | select_random_points | select_random_ranges | oltp_read_write |
|---|---|---|---|---|---|
| 8 | 15910 | 16540 | 5359 | 2646 | 443 |
| 16 | 21945 | 17022 | 5999 | 2915 | 668 |
| 32 | 25614 | 17356 | 6355 | 3065 | 857 |
| 64 | 31782 | 17410 | 6690 | 3088 | 1085 |
| 128 | 35009 | 17584 | 6713 | 3161 | 1561 |
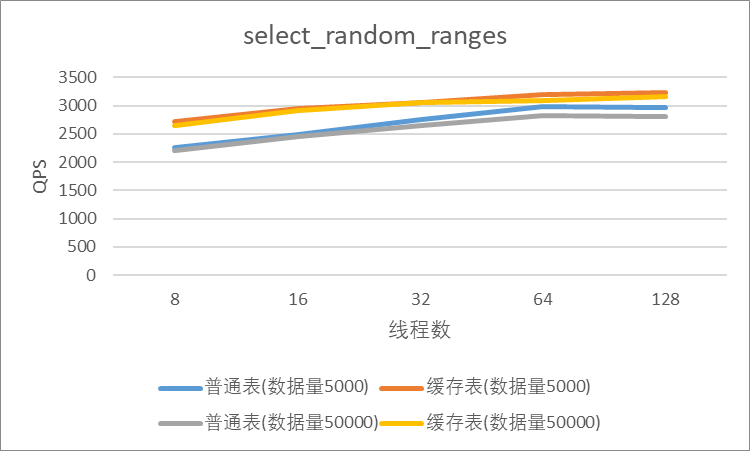
三.性能对比




五、遇到的问题
1.目前 TiDB 对于每张缓存表的大小限制为 64 MB(所有 key-value 记录的总大小),因此太大的表无法缓存在内存中。尝试将50w数据的表改为缓存表时报错ERROR 8242 (HY000): 'table too large' is unsupported on cache tables。当然这本身不是什么问题,不过想把一些相对大一些的表也缓存起来达到加速读写的目的可能暂时无法实现。
2.测试过程中缓存表性能出现了不稳定的情况,有些时候缓存表反而比普通表读取性能差,使用 trace 语句(TRACE SELECT * FROM sbtest1;)查看发现返回结果中出现了regionRequest.SendReqCtx,说明 TiDB 尚未将所有数据加载到内存中,多次尝试均未加载完成。把tidb_table_cache_lease调整为10后没有出现该问题。在asktug中向研发大佬提出了这个问题得到了解答。根据https://github.com/pingcap/tidb/issues/33167中的描述,当机器负载较重时,load table需要3s以上 ,但是默认的tidb_table_cache_lease是3s, 表示加载的数据是立即过时,因此需要重新加载,并且该过程永远重复。导致了浪费了大量的 CPU 资源并降低了 QPS。目前可以将tidb_table_cache_lease的值调大来解决,该问题在master分支中已经解决,后续版本应该不会出现。
3.根据测试结果,写入较为频繁的情况下缓存表的性能是比较差的。在 lease 过期之前,无法对数据执行修改操作。为了保证数据一致性,修改操作必须等待 lease 过期,所以会出现写入延迟。例如tidb_table_cache_lease为10时,写入可能会出现较大的延迟。因此写入比较频繁或者对写入延迟要求很高的业务不建议使用缓存表。
六、总结
在6.0版本之前,对于小表热点问题我们可以通过load split、follower read、stale read等方式去缓解,6.0之后提供了一种全新的功能缓存表去解决小表读热点问题。缓存表剑走偏锋,它的机制决定了使用场景目前仅限于表的数据量不大 的只读表,或者几乎很少修改的小表,但在它的使用场景下相较于其他方式能够提供更好的性能。
本次测试除了各种读性能测试外有写操作的只测试了oltp_read_write(读写混合操作)的场景。由于缓存表使用了lease机制,为了保证缓存的一致性,写操作可能会产生较大的延迟,因此在读写操作都比较频繁的oltp_read_write的场景下测试性能低于普通表符合预期。类似这种写操作较为频繁的业务则不建议使用缓存表,也许更适合放到nosql例如redis中去。在oltp_point_select(点查,条件为唯一索引列),oltp_read_only(只读操作,包含聚合、去重等),select_random_points(随机点查,主键列的selete in操作)和select_random_ranges(随机范围查询,主键列的selete between操作)的性能测试中相较于普通表都大幅提高了访问性能。综上,虽然缓存表目前的使用场景相对比较单一,但是在合适的场景下确实是一个解决了业务痛点的好功能,也期待在后续的版本中能有更高的稳定性和更优秀的性能表现。